















































软件

产品


1. 减少输出变量,增大输出步长
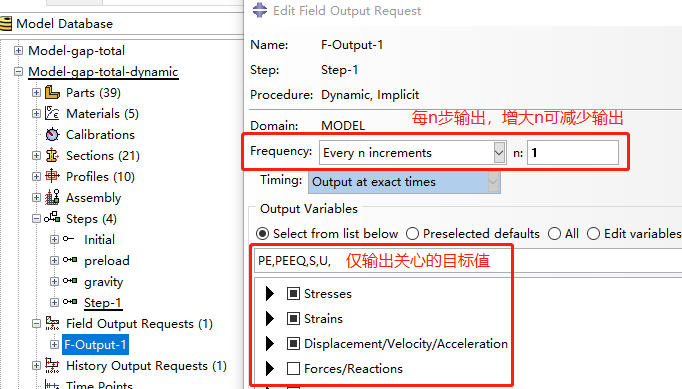
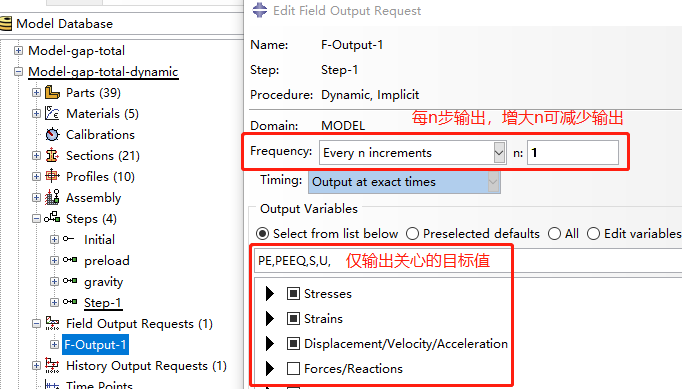
首先对输出的场变量(Field Output Requests)进行筛选,仅选择后处理分析中你所关注的目标变量,例如应力S、位移U等。
或是可以在预计步长较多且较密集的Job分析时,通过适当降低输出频率,即将输出的间隔n放大,比如可以取2或5等,可以在保证结果精度的情况下将计算时间近似减为1/n倍。当然不建议取值过大,会错过关键点的结果提取。
以上两种均是通过减少计算结果的磁盘写入时间来达到加速计算的效果。
2. 通过改变积分方法(取决于模型适用情况)
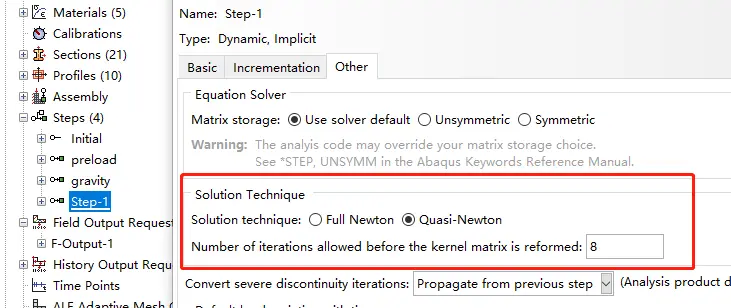
以隐式动态分析(Dynamic, Implicit)为例,定义Step中的Other选项卡中,可以选择积分方法为全牛顿法或是准牛顿法。两者的主要区别在于,准牛顿法是在规定的迭代次数后进行一次刚度矩阵的更新,而不是每次迭代都进行更新。这在对于刚度变化不大的结构分析中可以减少计算的代价从而加快速度。但需要强调的是,这并不适用于所有结构,需要根据自己的模型条件或是试算结果决定选用哪种积分方法。

3. 利用并行计算
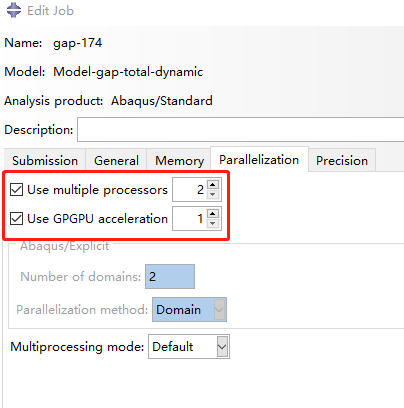
通过利用多处理器和GPGPU实现并行计算也是ABAQUS中可以直接设置的加速技巧。对于GPGPU的加速原理则主要是利用了其比CPU强大得多的并行计算能力,配合CPU的逻辑处理能力以达到速度最大化。需要注意的是,ABAQUS中GPGPU只能用于隐式计算,而不能用于显式。
但是,并不是分配越多的CPU或GPGPU计算就越快,因为线程的分配是需要代价的,在一些情况下(例如参考文献[1]中提到的自由度数量有限或是接触和约束的问题),会导致无法实现并行计算,导致ABAQUS直接报错的情况。
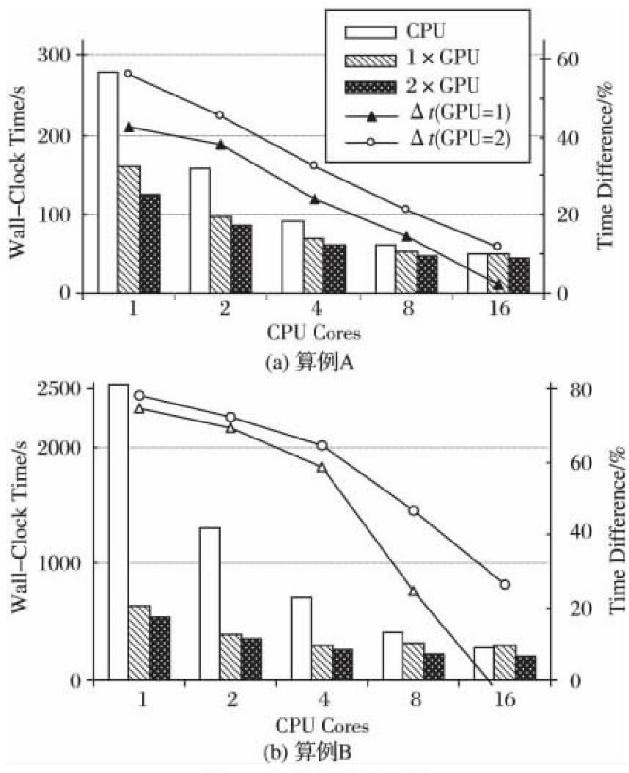
在文献[2]中作者对比了不同CPU和GPGPU的数量对于计算时间(这里指真实时间)的对比研究,如下图所示可做参考。
对于笔者来说,最常用的应该就是取ABAQUS的默认值,即2CPU+1GPGPU,如下图所示(Edit Job Parallelization)。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















