





































































分布式锁
什么是锁?
使用锁的目的是为了控制程序的执行顺序,防止共享资源被多个线程同时访问。为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行,那么需要在某个地方做个标记,这个标记必须每个线程都能看到,当标记不存在时可以设置该标记,其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。这个标记可以理解为锁。
不同地方实现锁的方式也不一样,只要能满足所有线程都能看得到标记即可。如 Java 中 synchronize 是在对象头设置标记,Lock 接口的实现类基本上都只是某一个 volitile 修饰的 int 型变量其保证每个线程都能拥有对该 int 的可见性和原子修改,linux 内核中也是利用互斥量或信号量等内存数据做标记。
单机应用中,如果我们想要控制某个时刻只有一个线程去执行某段代码或者修改某个变量,可以使用JDK自带的锁,比如Synchronized,ReentrantLock等。但是在微服务体系中,往往单个服务会部署在多个节点上,这个时候想要控制某段代码或者变量同一时刻只有一个线程可以访问的话,使用JDK自带的锁就不行了,这个时候就需要引入分布式锁。
场景:我们的程序需要在用户订单状态变更的时候给用户微信小程序发一条消息,当然,这个接口也是微信提供的,为了校验权限,微信提供的接口需要调用方传入access_token(access_token的有效期只有两个小时,并且一旦调用获取access_token的接口,上一次获取的access_token就失效了)。这就需要我们在调用获取access_token的接口的时候,保证同一时刻只有一个线程执行。否则,可能A线程刚刚获取到access_token,准备使用这个access_token去发送消息的时候,B线程突然也进来去执行获取access_token的操作,这就导致A线程获取的access_token失效了,发送消息也会失败。
分布式锁如何实现?
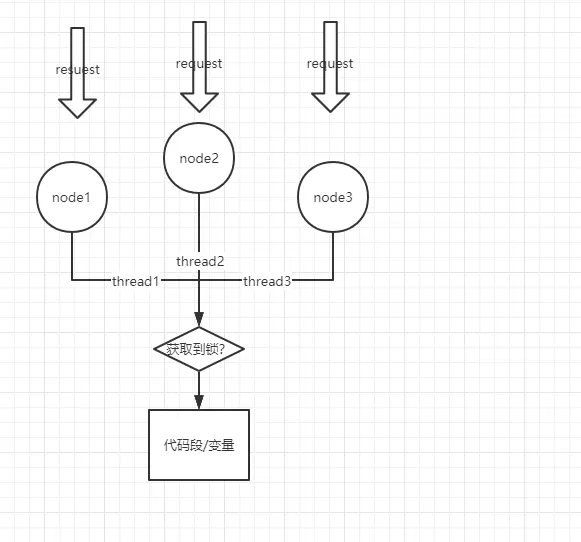
如上图:node1,node2,node3是部署在不同物理节点的同一服务,同一时刻,三个请求分别打到三个节点上,
每个节点都会由本结点的JVM启动一条线程去处理这个请求,假设三个线程thread1,thread2,thread3正好在同一时刻到达统一代码段,但是该段代码同一时刻只能有一个线程执行,这个时候就需要让这三个线程去竞争这个锁,只有获取到锁的线程才可以去执行这段代码,其他两个线程需要去阻塞等待或者直接返回。
很明显,这个分布式锁需要对这三个线程都是可见的,我们可以把这个分布式锁看作是一个资源,只有获取到资源的线程才可以继续向下执行(与单机程序中的锁很相似),那么如何让这个锁资源对不同节点的线程都可见呢?
那么就需要引入第三方来管理这个锁资源,如果有节点想要去获取锁,直接与这个第三方交互即可。至于锁状态值或者锁中数据的维护,都交由这个第三方来维护。节点只需要去请求下是否可以获取锁,然后这个第三方把结果告诉节点即可。这个第三方需要支持如果同时有三个请求想要获取锁,那么只能把这个锁给到其中的一个,其他两个请求要么阻塞,要么直接返回获取锁失败。
由此,我们可知这个管理节点的第三方应该是类似数据库,缓存这样的支持分布式系统的全局存储系统。
常见的分布式锁: 基于数据库,基于缓存,基于zookeeper,基于etcd等
分布式锁特性
考虑到JDK中锁的特性,我们大概可以得到分布式锁的特性如下:
1.互斥性:这个应该是分布式锁的基本特性,或者说也是锁的基本特性,保证资源(这里指共享代码段或者共享变量)同时只能有一个节点的某个线程访问;
2.可重入性:类似于ReentrantLock,同一服务节点的相同线程,允许重复多次加锁;
3.锁超时:特性与本地锁一致,一旦锁超时即释放拥有的锁资源;
4.非阻塞:支持获取锁的时候直接返回结果值(true or false),而不是在没有获取到锁的时候阻塞住线程的执行;
5.公平锁与非公平锁:公平锁是指按照请求加锁的顺序获得锁,非公平锁请求加锁是无序的。
以上的特性不是所有锁都需要支持的,根据具体的业务场景,可以只使用其中的某一种或者几种特性。
考虑到单点问题,这个分布式锁最好是集群模式,支持高可用,同时获取锁和释放锁的性能要好。
常见的分布式锁实现
-
基于MySQL数据库实现分布式锁
基于MySql实现分布式锁有三种方式,分别是基于唯一索引,悲观锁与乐观锁
基于MySql实现分布式锁主要是利用MySql自身的行锁机制,保证对于某一行,同时只能由一个线程对其查询或者更新(这就实现了分布式锁的最基本的特性:互斥性),而能够访问该行的线程即可以认为是获取到分布式锁的线程。
1.基于唯一索引实现
我们考虑一种最简单的MySQL实现分布式锁的方式:创建一个锁表,在表中添加一列名为lock_name,为这一列添加唯一索引unique key,对于某一个方法,如果有多个节点的多个线程同时访问,那么让这些线程去执行insert,由于唯一索引的存在,只会有一个线程插入成功,那么这个插入成功的线程就可以认为是获取到分布式锁的线程。
CREATE TABLE lock(
idint(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
lock_name varchar(64) NOT NULL DEFAULT '' COMMENT '锁名',descvarchar(1024) NOT NULL DEFAULT '备注信息',update_timetimestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成',PRIMARY KEY (
id),
UNIQUE KEYuidx_lock_name(lock_name) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';获取锁执行insert语句,如果插入成功则说明可以成功获取到锁
insert into lock(lock_name,desc) values (‘lock_name’,‘desc’)释放锁则执行delete语句
delete from lock where lock_name='lock_name'拓展:
insert为非阻塞的,一旦插入失败就返回结果了,如果想要实现阻塞可以使用while循环;
要实现公平锁,可以引入一张表,记录因为插入失败而阻塞的线程,一旦锁被释放,被阻塞的线程可以根据插入的先后顺序来决定自己是否可以获取锁;
要实现可重入性,需要在锁表中增加一列,记录获取锁的服务节点信息与线程信息,获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了;
要实现锁超时,需要在锁表增加一列,记录锁失效的时间,同时增加一个定时任务系统,定时扫描锁表中超时的记录,删除该条记录从而释放锁。
2.基于数据库排他锁实现
基于数据库排他锁for update实现,使用select ....... for update成功的线程可以获取到锁,失败的线程会被阻塞。而事务执行完毕,commit事务的时候就相当于释放了锁资源。
@Transaction public void lock(String lockName) { ResourceLock rlock = exeSql("select * from resource_lock where resource_name = lockName for update"); if (rlock == null) { exeSql("insert into resource_lock(reosurce_name,owner) values (lockName, 'ip')"); } /** 业务逻辑 **/ // 最后事务执行完毕,提交的时候就表示锁可以释放了 }查询和插入的操作放在一个事务之中,事务开始执行select ... for update查询的时候,代表有请求进来想要获取锁,如果查询成功或者发现锁表中没有该条记录,那么说明当前的请求可以获取该分布式锁资源。获取到锁资源之后,执行业务逻辑,业务逻辑执行完毕,事务提交,那么锁资源就被释放了。
MySql Innodb引擎中可以通过设置innodb_lock_wait_timeout控制全局的锁超时时间,默认是50s。
排他锁需要事务资源,会占用数据库连接,因为每个请求过来都会去for update,并且只有一个线程请求可以真正执行,其他的请求会持有连接资源阻塞住等待已经获取锁的线程释放。这样会造成大量的连接被占用,产生连接爆满的问题。
显然,使用排他锁的话很难实现锁重入。并且由于innodb_lock_wait_timeout是针对全局的,所以对锁超时的支持也不太好。
3.基于数据库乐观锁实现
我们知道,mysql乐观锁机制是在表中增加了version列,记录版本号。之后先查询某一行数据将版本号取出。更新的时候对版本号进行比较,一致的话,说明没有其他请求修改该条记录,那么就可以执行更新操作,否则的话无法更新。
select * from resource where resource_name = xxx update resource set version= 'newVersion' ... where resource_name = xxx and version = 'oldVersion很显然,同一时刻只能有一个请求成功更新该条记录,那么我们就可以把成功更新该条记录的线程作为获取到分布式锁的线程。
@Transaction public void lock(String lockName) { ResourceLock rlock = exeSql("select * from resource_lock where resource_name = lockName"); if (rlock == null) { exeSql("insert into resource_lock(reosurce_name,owner,version) values (lockName, 'ip',1)"); } /** 业务逻辑 **/ Integer count = exeSql("update resource_lock set version=version+1 where resource_name = lockName and version=#{version}"); if(count == 1) { // 成功获取到分布式锁,可以提交本次事务 } else { // 使用while重复执行select,update来获取分布式锁资源或者直接回滚本地事务 } }乐观锁的实现要先执行select再执行update,如果冲突比较多的话,大量的线程请求会执行CAS耗费CPU时间。
总结:基于数据库实现分布式锁,主要就是利用数据库自身的锁机制,保证插入,查询或者更新的排他性,但是由于数据库本身锁的开销以及性能,这种使用场景并不太多。
-
基于Redis实现分布式锁
Redis除了用作缓存之外,也可以用来作为分布式锁。利用redis天然的支持分布式系统的特性以及某些命令的使用,可以较好的来实现分布式锁。redis的读写性能比较数据库来说也有极大的提升,目前也是一种较为流行的分布式锁解决方案。
1.SetNX命令实现分布式锁
SETNX key value 将key的值设置为value,当且仅当key不存在的时候
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写
redis 2.6.12之前的版本是使用setnx+expire命令来实现分布式锁,expire命令是给锁设置过期时间避免发生死锁。
public static boolean lock(Jedis jedis, String lockKey, String requestId, int expireTime) { // 使用requestId作为value是防止出现线程B把线程A的锁给释放了 Long result = jedis.setnx(lockKey, requestId); //设置锁 if (result == 1) { //获取锁成功 //若在这里程序突然崩溃,则无法设置过期时间,将发生死锁 //通过过期时间删除锁 jedis.expire(lockKey, expireTime); return true; } return false; }由于上面setnx命令与expire命令非原子性,那么在获取锁成功准备去设置锁超时时间的时候,极端情况下系统崩溃了,那么该锁就没有设置超时时间,无法释放锁资源。
为了解决上面的问题,有两种方案:
1)方式一:lua脚本
既然是由于setnx与expire命令非原子性导致的,那么我们可以使用lua脚本来实现将这两个命令设置为原子性的。
// 加锁脚本,KEYS[1] 要加锁的key,ARGV[1]是UUID随机值,ARGV[2]是过期时间 private static final String SCRIPT_LOCK = "if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then redis.call('pexpire', KEYS[1], ARGV[2]) return 1 else return 0 end"; // 解锁脚本,KEYS[1]要解锁的key,ARGV[1]是UUID随机值 private static final String SCRIPT_UNLOCK = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";2)方式一:设置value为锁过期时间
public static boolean wrongGetLock2(Jedis jedis, String lockKey, int expireTime) { long expires = System.currentTimeMillis() + expireTime; // 设置锁的过期时间 String expiresStr = String.valueOf(expires); // 如果当前锁不存在,返回加锁成功 if (jedis.setnx(lockKey, expiresStr) == 1) { return true; } // 如果锁存在,获取锁的过期时间 String currentValueStr = jedis.get(lockKey); if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) { // 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间 String oldValueStr = jedis.getSet(lockKey, expiresStr); if (oldValueStr != null && oldValueStr.equals(currentValueStr)) { // 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才有权利加锁 return true; } } // 其他情况,一律返回加锁失败 return false; } // 释放锁 public static void wrongReleaseLock1(Jedis jedis, String lockKey) { jedis.del(lockKey); }假设锁过期了,这个时候多个线程来请求获取锁,执行到jedis.getSet(lockKey, expiresStr)方法的时候,只有一个线程获取到的旧值是与原来的currentValueStr相同的,因为set会更新对应的lockKey的值,这之后的线程再调用getSet方法的时候获取到的值与currentValueStr就不同了。当然,这也会导致lockKey的值被覆盖。除了被覆盖的问题,还有就是各个客户端自己生成过期时间,而保证不同客户端时间的同步也是一个问题。还有就是这种情况下的分布式锁不具有标识,无法区分是哪个客户端加的锁,可能导致客户端A加的锁被客户端B释放了。
客户端A获取到分布式锁执行自己的程序,正常情况下,程序执行完毕需要释放锁资源,但是在某次程序执行的时候,由于调用第三方服务超时了,在没有执行到程序结束的时候,锁就已经过有效期了,这个时候客户端B就可以获取锁资源去执行自己的程序,在客户端B执行的过程中,客户端A执行的程序结束了,这个时候客户端A仍然执行释放锁的操作,结果就会把客户端B的锁给释放了。
2.SET key value [EX seconds] [PX milliseconds] [NX|XX]命令实现分布式锁
SET key value [EX seconds] [PX milliseconds] [NX|XX]
可选参数
从 Redis 2.6.12 版本开始, SET 命令的行为可以通过一系列参数来修改:
EX second:设置键的过期时间为second秒。SET key value EX second效果等同于SETEX key second value。PX millisecond:设置键的过期时间为millisecond毫秒。SET key value PX millisecond效果等同于PSETEX key millisecond value。NX:只在键不存在时,才对键进行设置操作。SET key value NX效果等同于SETNX key value。XX:只在键已经存在时,才对键进行设置操作。
通过设置EX PX NX 这三个参数,可以实现setnx与expire命令的结合。这个是Redis 2.6.12 版本之后提供的原子性的命令。
// 获取锁 public static boolean tryGetDistributedLock(String lockKey, String requestId, int expireTime) { Jedis jedis = RedisUtil.getJedis(); String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime); if ("OK".equals(result)) { return true; } return false; } // 释放锁,使用lua脚本 public static boolean tryGetDistributedLock(String lockKey, String requestId, int expireTime) { Jedis jedis = RedisUtil.getJedis(); String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId)); // 执行lua脚本 if (1L.equals(result)) { return true; } return false; }3.Redission分布式锁
Redission是基于redis实现的分布式锁,主要使用的是redis的hash结构
HSET key field value
将哈希表
key中的域field的值设为value。如果
key不存在,一个新的哈希表被创建并进行 HSET 操作。如果域
field已经存在于哈希表中,旧值将被覆盖。HINCRBY key field increment
为哈希表
key中的域field的值加上增量increment。增量也可以为负数,相当于对给定域进行减法操作。
HEXISTS key field
查看哈希表
key中,给定域field是否存在。加锁lua源码
<
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。

 技术文档
技术文档
 推荐好文
推荐好文







 155-2731-8020
155-2731-8020