















































软件

产品


随着分布式数据库日渐成熟,在推广使用上开始步入深水区。在这一过程中,对企业的架构、运维、开发都带来不小的冲击,如何快速掌握这一新技术,尽快落地成为大家关注的焦点。本文从开发者的视角出发,讨论使用分布式数据库所面临的难点之一:数据分片策略,这也是阻碍很多企业上到分布式数据库的核心问题。
分布式数据库的核心能力之一,就是通过数据分片存储,来承载更大的数据规模和计算负载。数据分片,是把数据库横向扩展到多个物理节点上的一种分布式技术。可以理解为将表数据按照特定的分片规则水平切分成若干片段(shard),使这些数据片段分布在不同物理节点上。数据分片从大类可分为垂直分片和水平分片,前者是按业务类别进行拆分,常见为业务拆库;后者则是以字段为依据,按照一定策略拆分到若干表中。本文后面所谈的数据分片,是针对后者。那么如何将数据从单体更换为分布式,这就需要考虑数据分片策略。数据分片策略包括分片算法、数据分布、分布关系等,简单描述参见下表。
 图片
图片
业内分布式数据库产品,针对数据分片策略通常有三种做法。一种是基于主键/唯一索引/隐含主键等做统一数据分片,即用户无需人为设置分片策略;一种是开放若干数据分片算法,用户可自行创建数据对象时人为指定;还有一些数据库中间件产品,支持更为灵活的分片方式,可以让用户自行扩展。上面三种,我们可命名为内置、开放、自定义。下面从开发者角度,简单对比下这几种方式。
 图片
图片
这里解释一下:
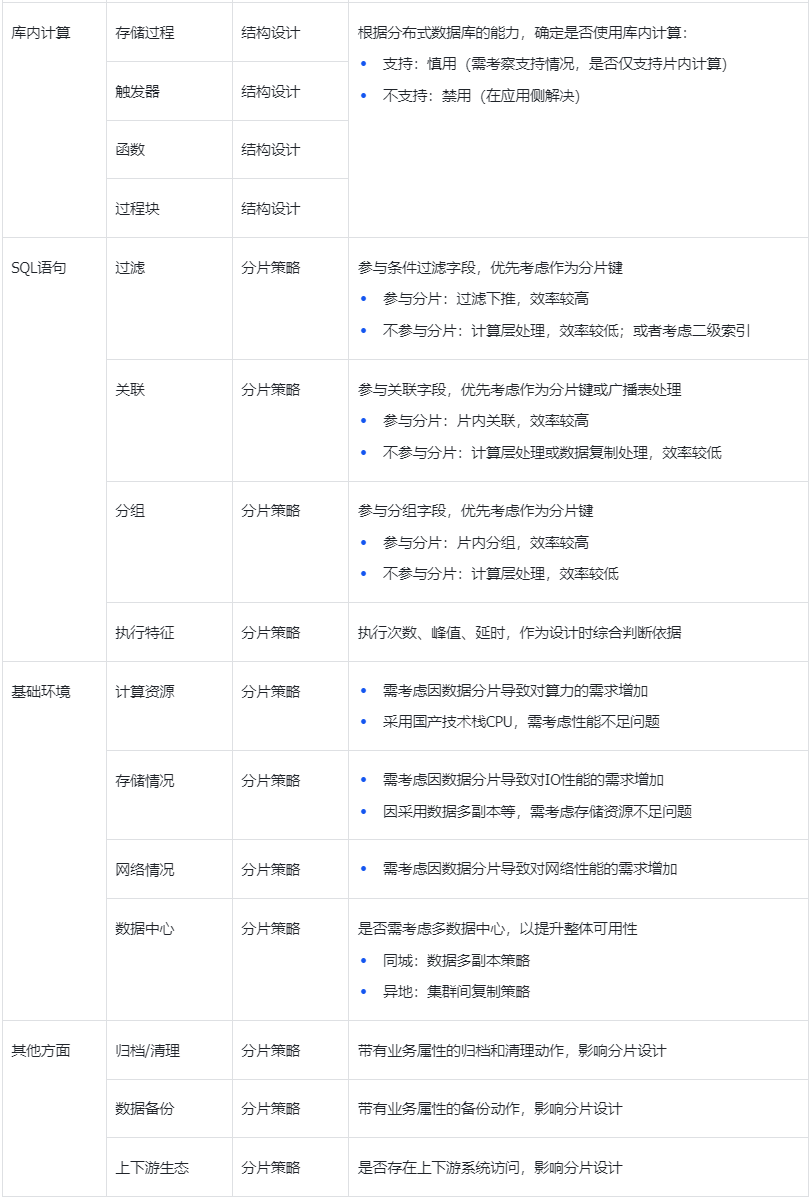
除了第一种方式外,其余两种都涉及一个问题就是现有数据对象如何拆分?好的拆分策略,一定是兼顾业务模型、性能最佳、稳定可靠、研发改造、运维难点等多种因素下,结合分布式数据库的特点而做的最优解,这是在多种因素下平衡的结果。在具体实施上,需要收集大量信息后才能做出决定,下面将主要部分整理为一个表格。
 图片
图片
 图片
图片
从上表可见,数据分片设计过程中,需考虑的问题很多,是一个多维立体的模型分析过程。包括对企业的业务流、数据流、数据模型、业务特征、基础环境等诸多方面的考虑。上述还需要结合分布式架构数据库的能力理解才能得出一个相对“适合”的设计方案。这对于企业来说是非常痛苦的,也是阻碍企业上到分布式数据库的难点之一。不能将上述包袱完全推给用户去完成,而是尽量在数据库产品侧给出答案,即产品需具备数据分片优化推荐功能。如果分片设计不合理,可能造成影响到业务系统的稳定可靠、服务体验,往往服务体验是忽快忽慢且最可怕是某一些时刻或者业务场景是最慢的,从而导致排错分析的困难复杂增加。当然,开始设计很难做到十全十美,但系统在运行中经过不断摸索后还需数据库具备一定的在线分片调整能力,例如针对分片类型或分片字段的调整。在这一过程中要做到不中断现有业务服务的正常运行,其次要做到尽量少地影响现有业务服务的性能体验(也即控制资源占用对生产环境的业务服务影响),最后要做到尽量快地完成分片信息的调整。
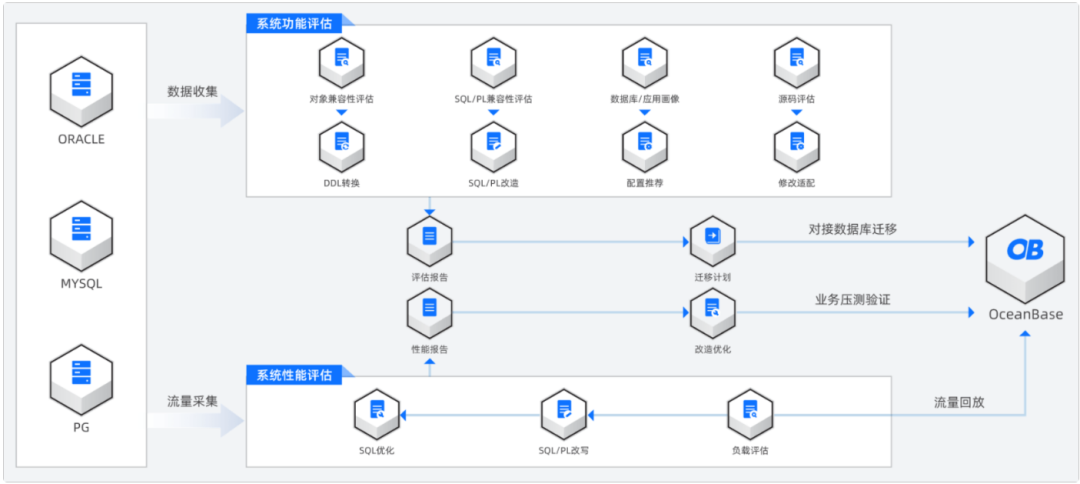
目前国内很多分布式数据库厂商都加强了迁移能力的支持,一般是通过外置工具的方式提供收集、评估、辅助迁移、验证等一系列流程的支持。下图是以OceanBase的OMA工具举例,说明其提供的支持能力。
 图片
图片
通过上图可见,产品针对数据分片策略部分做的不多,主要是对兼容类的评估工具;即根据数据库自身能力,评估原有对象、SQL语句需要做哪些改造等。尚没有实现数据分片策略的推荐工作,处于空白。其实去年公众号也发布过一篇文章,就是想通过小工具去完成这一过程,只是目前还未看到有厂商产品支持。相信未来这一能力得到支持后,将加快国内企业选择分布式数据库实践之路。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















