















































软件

产品


分层架构(layered architecture)是最常见的软件架构,也是事实上的标准架构。如果你不知道要用什么架构,那就用它。
这种架构将软件分成若干个水平层,每一层都有清晰的角色和分工,不需要知道其他层的细节。层与层之间通过接口通信。
虽然没有明确约定,软件一定要分成多少层,但是四层的结构最常见。
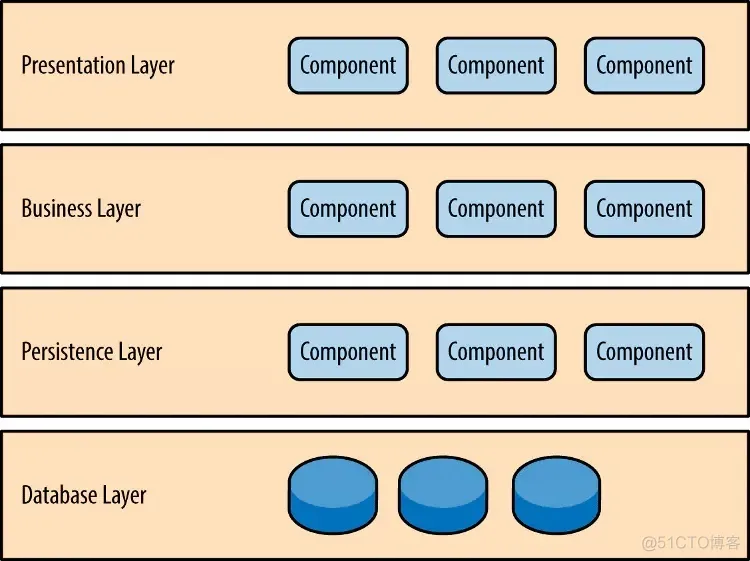
用户UI界面,负责视觉和用户互动
实现业务逻辑
提供数据,SQL 语句就放在这一层
保存数据
有的软件在逻辑层和持久层之间,加了一个服务层(service),提供不同业务逻辑需要的一些通用接口。
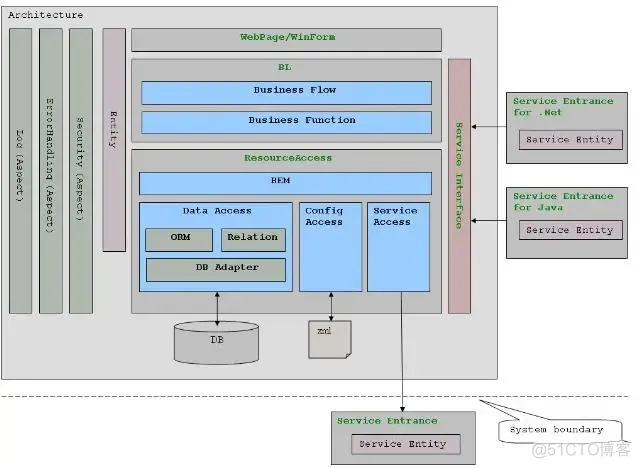
职责是数据的展现和采集,数据采集的结果通常以Entity object提交给BL层处理。Service Interface侧层用于将业务或数据资源发布为服务(如WebServices)。
职责是按预定的业务逻辑处理UI层提交的请求。
(1)Business Function 子层负责基本业务功能的实现。
(2)Business Flow 子层负责将Business Function子层提供的多个基本业务功能组织成一个完整的业务流。(Transaction只能在Business Flow 子层开启。)
职责是提供全面的资源访问功能支持,并向上层屏蔽资源的来源。
(1)BEM(Business Entity Manager)子层采用DataAccess子层和ServiceAccess子层来提供业务需要的基础数据/资源访问能力。
(2)DataAccess子层负责从数据库中存取资源,并向BEM子层屏蔽所有的SQL语句以及数据库类型差异。
DB Adapter子层负责屏蔽数据库类型的差异。
ORM子层负责提供对象-关系映射的功能。
Relation子层提供ORM无法完成的基于关系(Relation)的数据访问功能。
(3)ServiceAccess子层用于以SOA的方式从外部系统获取资源。
注: Service Entrance用于简化对Service的访问,它相当于Service的代理,客户直接使用Service Entrance就可以访问系统发布的服务。Service Entrance为特定的平台(如Java、.Net)提供强类型的接口,内部可能隐藏了复杂的参数类型转换。
(4)ConfigAccess子层用于从配置文件中获取配置object或将配置object保存倒配置文件。
在这些层之间传递数据。Entity侧层中包含三类Entity:
DB Entity,
Config Entity和
Service Entity。
Aspect贯穿于系统各层,是系统的横切关注点。通常采用AOP技术来对横切关注点进行建模和实现。
1)Securtiy Aspect:用于对整个系统的Security提供支持。
2)ErrorHandling Aspect:整个系统采用一致的错误/异常处理方式。
3)Log Aspect:用于系统异常、日志记录、业务操作记录等。
1)系统各层次及层内部子层次之间都不得跨层调用。
2)Entity object 在各个层之间传递数据。
3)需要在UI层绑定到列表的数据采用基于关系的DataSet传递,除此之外,应该使用Entity object传递数据。
4)对于每一个数据库表(Table)都有一个DB Entity class与之对应,针对每一个Entity class都会有一个BEM Class与之对应。
5)有些跨数据库或跨表的操作(如复杂的联合查询)也需要由相应的BEM Class来提供支持。
6)对于相对简单的系统,可以考虑将Business Function子层和Business Flow 子层合并为一个。
7)UI层和BL层禁止出现任何SQL语句。
异常可以分为系统异常(如网络突然断开)和业务异常(如用户的输入值超出最大范围),业务异常必须被转化为业务执行的结果。
1)DataAccess层不得向上层隐藏任何异常(该层抛出的异常几乎都是系统异常)。
2)要明确区分业务执行的结果和系统异常。比如验证用户的合法性,如果对应的用户ID不存在,不应该抛出异常,而是返回(或通过out参数)一个表示验证结果的枚举值,这属于业务执行的结果。但是,如果在从数据库中提取用户信息时,数据库连接突然断开,则应该抛出系统异常。
3)在有些情况下,BL层应根据业务的需要捕获某些系统异常,并将其转化为业务执行的结果。比如,某个业务要求试探指定的数据库是否可连接,这时BL就需要将数据库连接失败的系统异常转换为业务执行的结果。
4)UI层(包括Service层)除了从调用BL层的API获取的返回值来查看业务的执行结果外,还需要截获所有的系统异常,并将其解释为友好的错误信息呈现给用户。
以BAS系统为例。
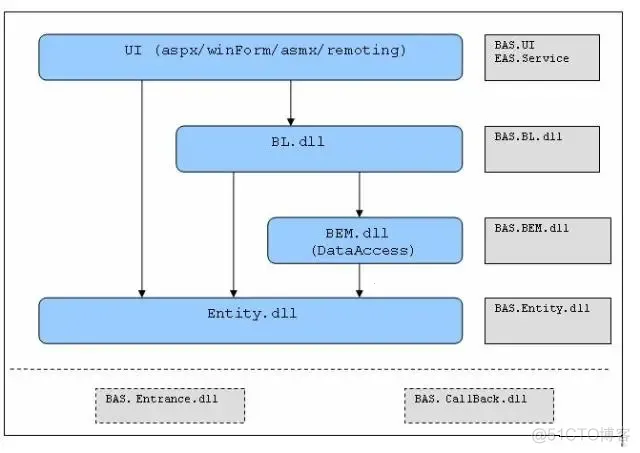
每个dll的根命名空间即是该dll的名字,如EAS.BL.dll的根命名空间就是EAS.BL。每个根命名空间下面可以根据需求的分类而增加子命名空间,比如,EAS.BL的子空间EAS.BL.Order与EAS.BL.Permission分别处理不同的业务逻辑。
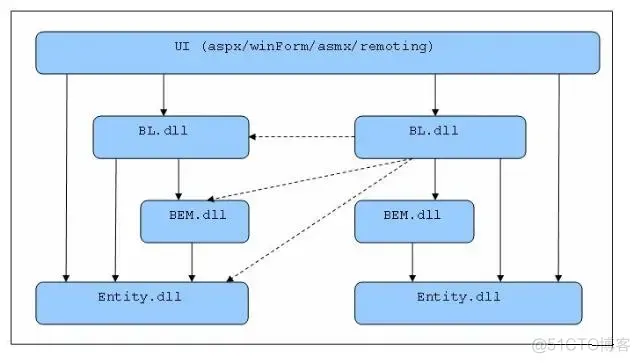
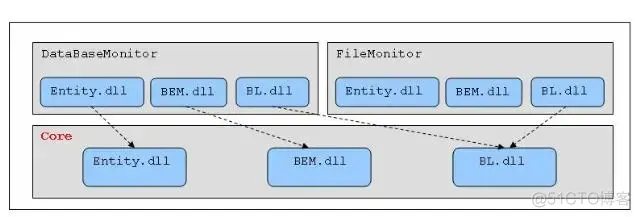
Core子项目中包含一些公共的基础设施,如错误处理、权限控制方面等。
7.发布服务与服务回调
以EAS系统为例
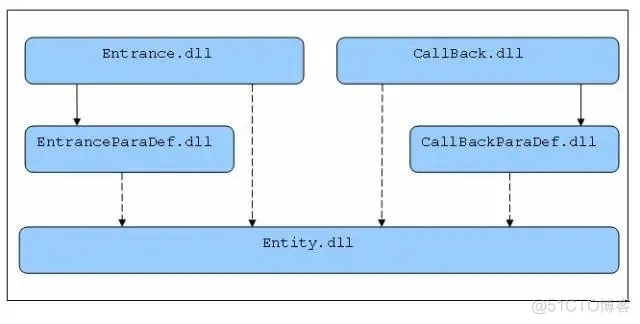
1)同UI层的Page一样,服务也不允许抛出任何异常,而是应该以返回错误码(int型,1表示成功,其它值表示失败)的形式来表明服务调用出现了错误,如果方法有返回值,则返回值以out参数提供。
2)如果BAS系统提供了WebService(Remoting)服务,则BAS必须提供BAS.Entrance.dll。 BAS.Entrance.dll封装了与BAS服务交换信息的通信机制,客户系统只要通过BAS.Entrance.dll就可以非常简便地访问BAS 提供的服务。
3)如果BAS需要通过WebService(Remoting)回调客户系统,则必须提供仅仅定义了接口的BAS.CallBack.dll,客户系统将引用该dll,实现其中的接口,并将其发布为服务,供BAS回调。
4)当WebService的参数或返回值需要是复杂类型――即架构图中的Service Entity,则Service Entity应该在对应的BAS.EntranceParaDef.dll或BAS.CallBackParaDef.dll中定义。 WebService定义的方法中的复杂类型应该使用Xml字符串代替(注意,Entrance和CallBack接口对应服务的方法的参数是强类型的),而Xml字符串和复杂类型对象之间的转换应当在BAS.Entrance.dll或BAS.CallBack.dll中实现。
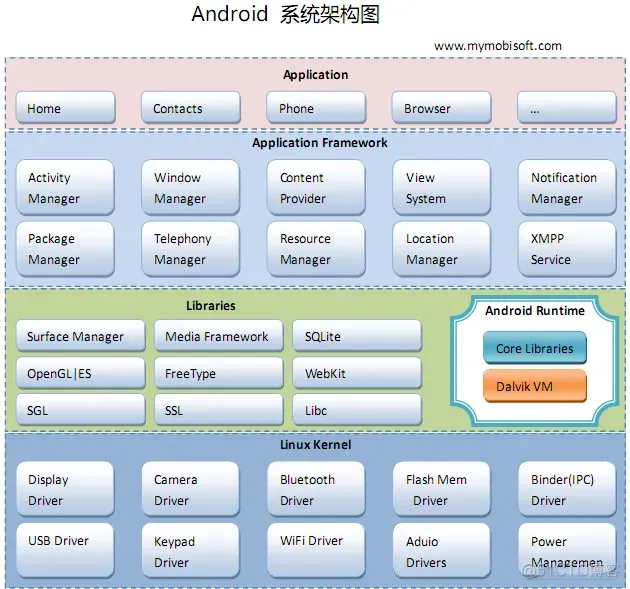
从上图中可以看出,Android系统架构为四层结构,从上层到下层分别是应用程序层、应用程序框架层、系统运行库层以及Linux内核层,分别介绍如下:
Android平台不仅仅是操作系统,也包含了许多应用程序,诸如SMS短信客户端程序、电话拨号程序、图片浏览器、Web浏览器等应用程序。这些应用程序都是 用Java语言编写的,并且这些应用程序都是可以被开发人员开发的其他应用程序所替换,这点不同于其他手机操作系统固化在系统内部的系统软件,更加灵活和个 性化。
应用程序框架层是我们从事Android开发的基础,很多核心应用程序也是通过这一层来实现其核心功能的,该层简化了组件的重用,开发人员可以直接使用其提 供的组件来进行快速的应用程序开发,也可以通过继承而实现个性化的拓展。
管理各个应用程序生命周期以及通常的导航回退功能
管理所有的窗口程序
使得不同应用程序之间存取或者分享数据
构建应用程序的基本组件
使得应用程序可以在状态栏中显示自定义的提示信息
Android系统内的程序管理
管理所有的移动设备功能
提供应用程序使用的各种非代码资源,如本地化字符串、图片、布局文件、颜色文件等
提供位置服务
提供Google Talk服务
从图中可以看出,系统运行库层可以分成两部分,分别是系统库和Android运行时,分别介绍如下:
系统库是应用程序框架的支撑,是连接应用程序框架层与Linux内核层的重要纽带。其主要分为如下几个:
执行多个应用程序时候,负责管理显示与存取操作间的互动,另外也负责2D绘图与3D绘图进行显示合成。
多媒体库,基于PacketVideo OpenCore;支持多种常用的音频、视频格式录制和回放,编码格式包括MPEG4、MP3、H.264、AAC、ARM。
小型的关系型数据库引擎
根据OpenGL ES 1.0API标准实现的3D绘图函数库
提供点阵字与向量字的描绘与显示
一套网页浏览器的软件引擎
底层的2D图形渲染引擎
在Andorid上通信过程中实现握手
从BSD继承来的标准C系统函数库,专门为基于embedded linux的设备定制
Android应用程序时采用Java语言编写,程序在Android运行时中执行,其运行时分为核心库和Dalvik虚拟机两部分。
核心库提供了Java语言API中的大多数功能,同时也包含了Android的一些核心API,如android.os、 android.net、android.media等等。
Android程序不同于J2me程序,每个Android应用程序都有一个专有的进程,并且不是多个程序运行在一个虚拟机中,而是每个Android程序都有一 个Dalivik虚拟机的实例,并在该实例中执行。Dalvik虚拟机是一种基于寄存器的Java虚拟机,而不是传统的基于栈的虚拟机,并进行了内存资源使用的优化 以及支持多个虚拟机的特点。需要注意的是,不同于J2me,Android程序在虚拟机中执行的并非编译后的字节码,而是通过转换工具dx将Java字节码转成dex格 式的中间码。
Android是基于Linux2.6内核,其核心系统服务如安全性、内存管理、进程管理、网路协议以及驱动模型都依赖于Linux内核。
Entity Framework的全称是ADO.NET Entity Framework,是微软开发的基于ADO.NET的ORM(Object/Relational Mapping)框架。
Entity Framework的主要特点:
架构图一:
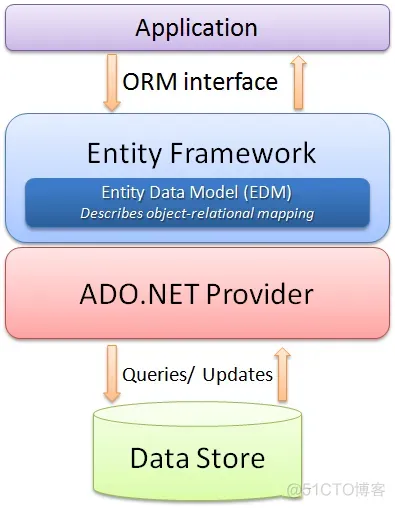
架构图二:

发布一企业技术架构图,供大家参考。
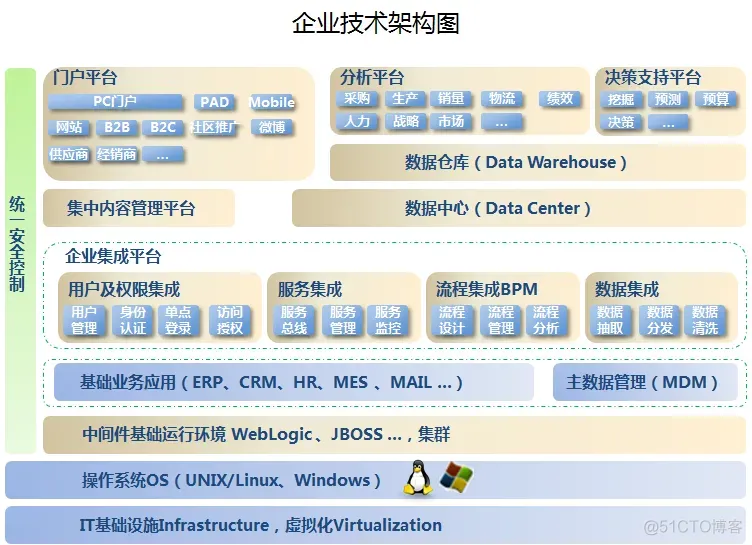
该技术架构图是本人根据多年企业技术架构经验而制定,是企业技术的总架构图,希望对CTO们有所借鉴。
简单说明:
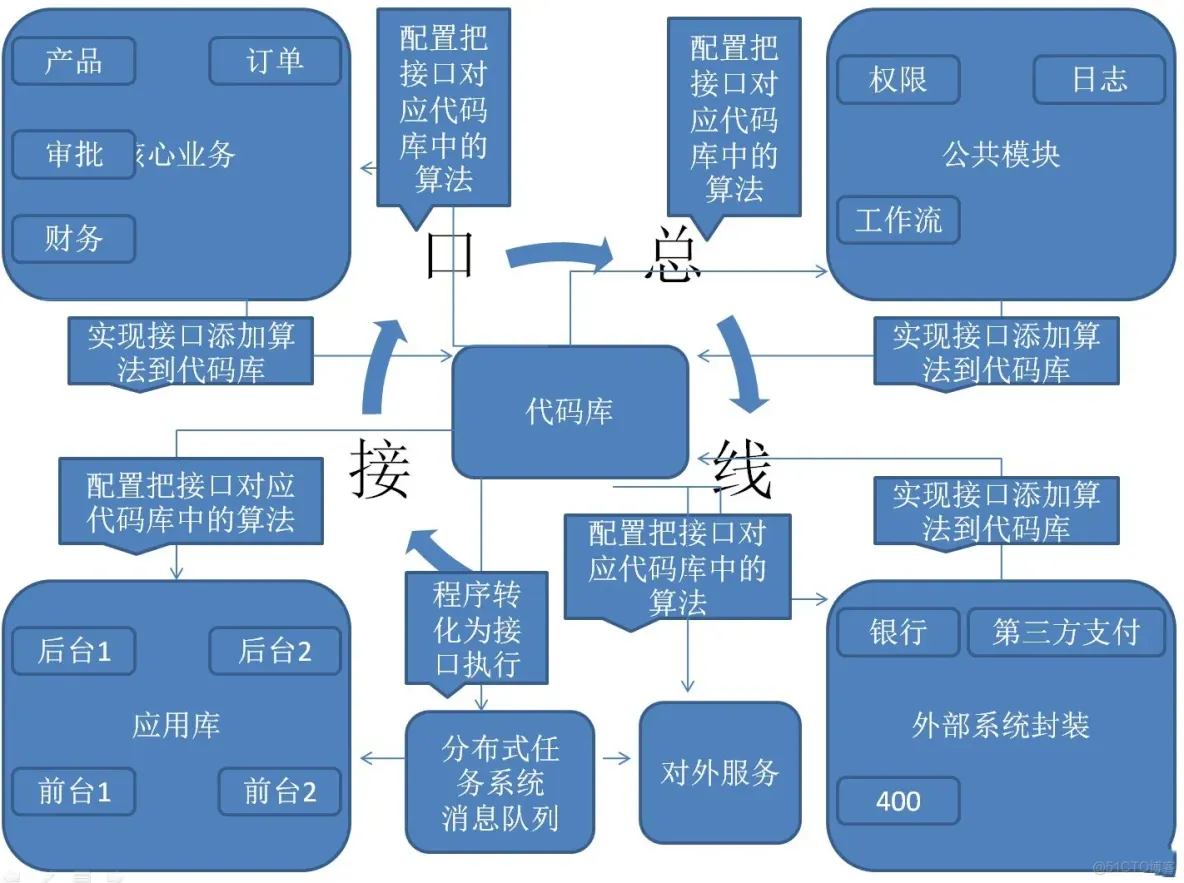
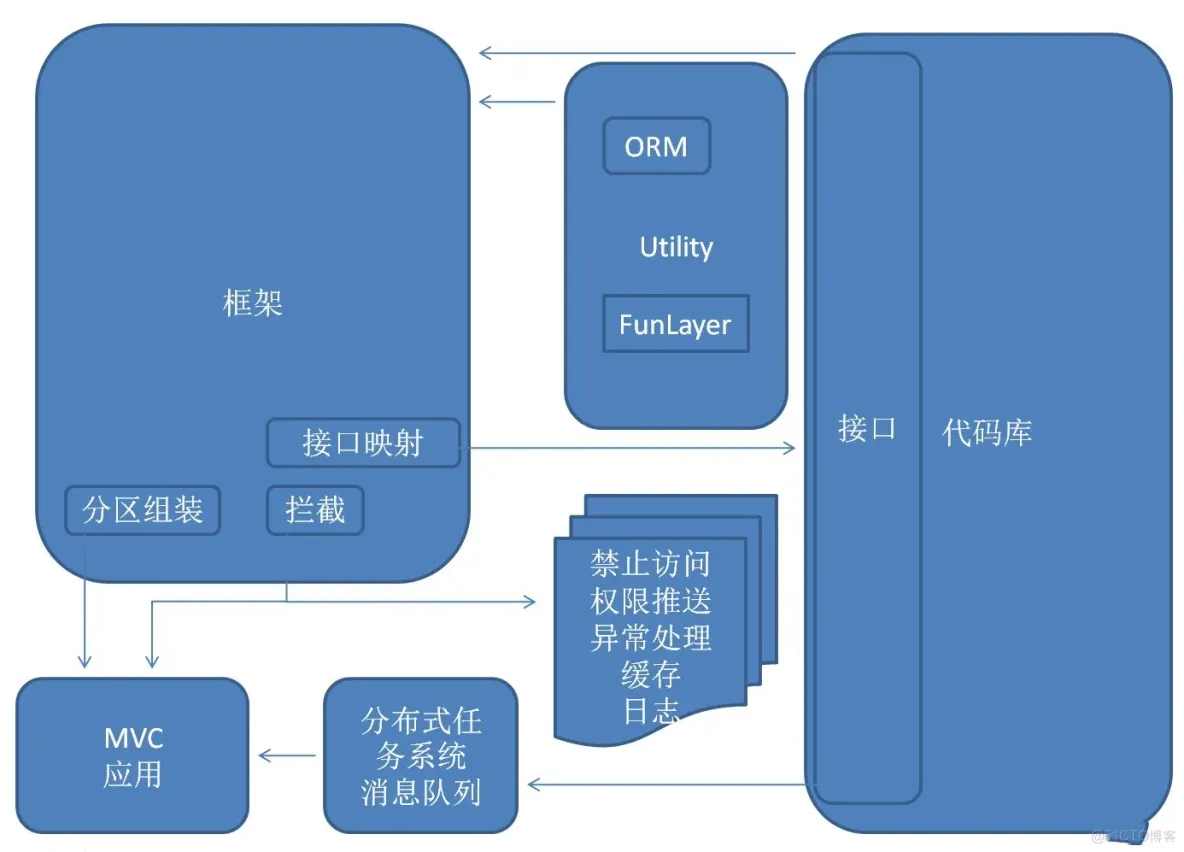
所有算法功能抽象成接口,其中大部分接口的方法都是泛型方法,是为了解决某一大类问题的
代码库包含现接口总线中接口的各种实现
提供用户的界面或者提供给外部的服务,是通过容器配置调用算法库中的代码来实现的各种应用
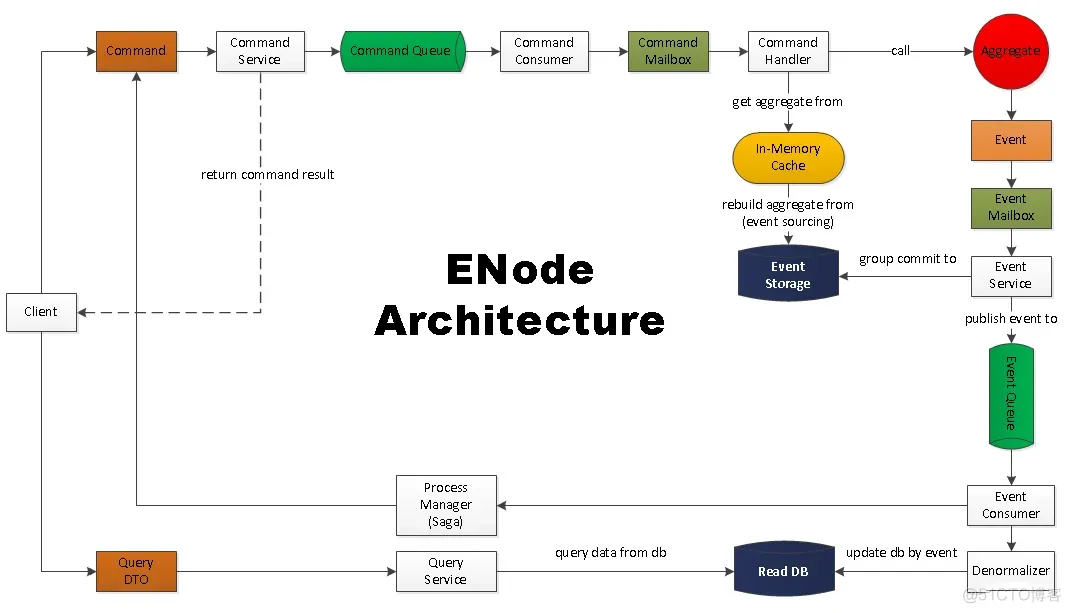
ENode是一个.NET平台下,纯C#开发的,基于DDD,CQRS,ES,EDA,In-Memory架构风格的,可以帮助开发者开发高并发、高吞吐、可伸缩、可扩展的应用程序的一个应用开发框架。
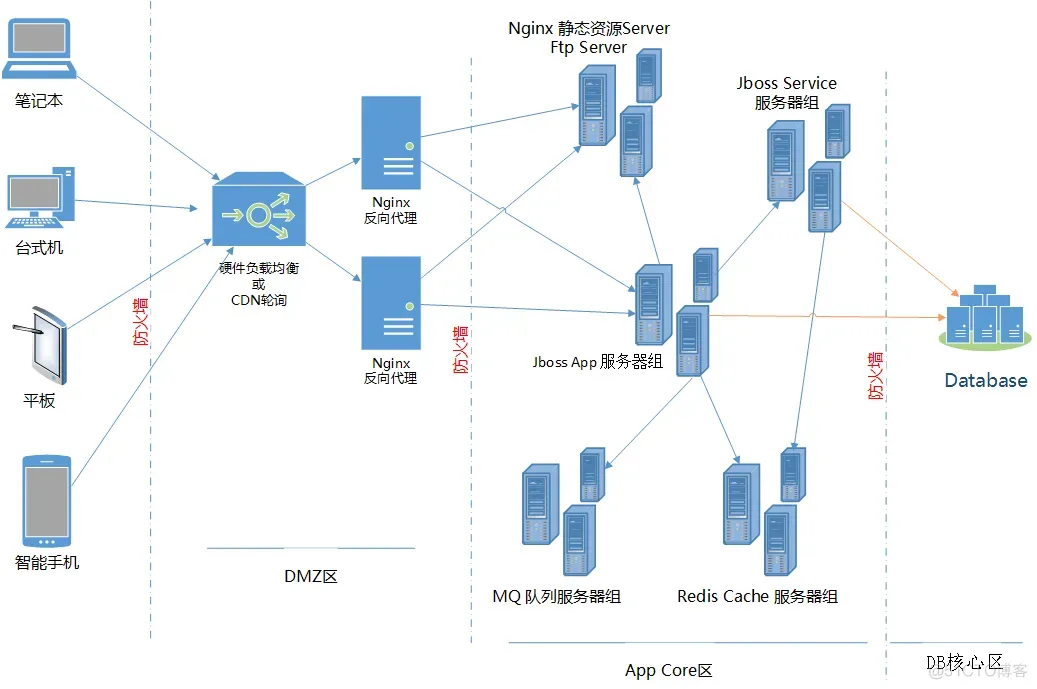
这是首要考虑的,以这张图为例,网络划分为3个区:
a) DMZ区可以直接公网访问,也可以 与App Core区互通,但不能直接与DB Core区互通 (通常这里放置 反向代理Web服务器)
b) App Core区能与DMZ区、DB Core区互通,但是无法直接从公网访问 (通常这里放置 应用服务器、中间件服务器之类)
c) DB Core区仅与App Core区互通 (通常这里放置 核心数据库)
上图中,除了“硬件负载均衡”节点外,其它节点都可以部署成集群(DB有点特殊,传统RDBMS要实现分布式/集群还是比较困难的,要看具体采用的数据库产品,并非所有数据库都能方便的做Sharding),Jboss本身可以通过Domain模式+mod_cluster实现集群、Redis通过Master/Slave以Sentinel方式可以实现HA、IBM MQ本身就支持集群、FTP Server配合底层储存阵列也可以做到HA、Nginx静态资源服务器自不必说
尽量采用开源成熟产品,jboss、redis、nginx、apache、mysql、rabbit MQ都是很好的选择。硬件负载均衡通常成本不低,但是效果明显,如果实在没钱,域名解析采用DNS轮询策略,也能达到类似效果,只不过可靠性略差。
常规企业应用中,传统关系型数据仍然是主流,但是no-sql经过这几年发展,技术也日渐成熟了,一些非关键数据可以适当采用no-sql数据库,比如:系统日志、报文历史记录这类相对比较独立,而且增长迅速的数据,可以考虑存储到no-sql db甚至HDFS、TFS等分布式开源文件系统中。
如果系统数据量级达到单机RDBMS的上限,尽早考虑Sharding方案,目前mysql在这方面比较成熟,其它数据库就不好说了。
web server、app server这些一般都可以通过集群实现横向扩张,满足性能日常增长的需求。最大的障碍还是DB,如果规模真达到了DB的上限,还是考虑换分布式DB或者迁移到“云”上吧。
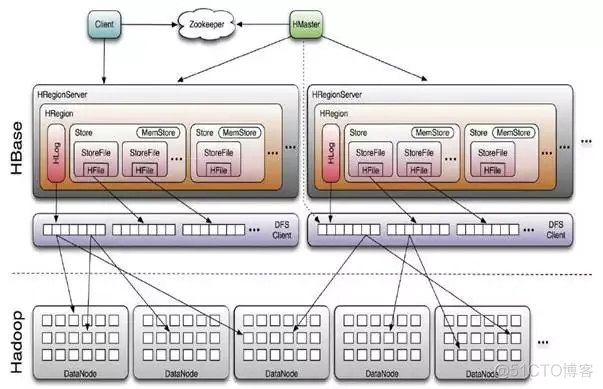
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行
主要负责Table和Region的管理工作:
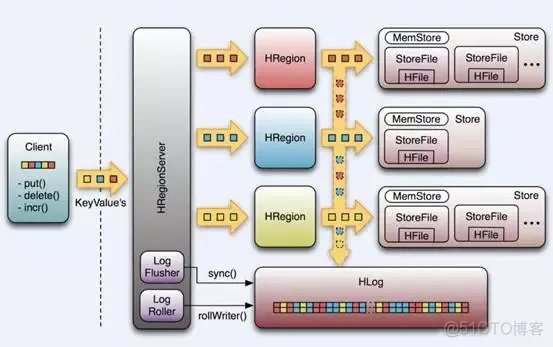
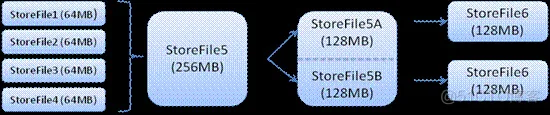
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 触发Compact合并操作 -> 多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除 -> 当StoreFiles Compact后,逐步形成越来越大的StoreFile -> 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个Region,Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
由此过程可知,HBase只是增加数据,有所得更新和删除操作,都是在Compact阶段做的,所以,用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能。
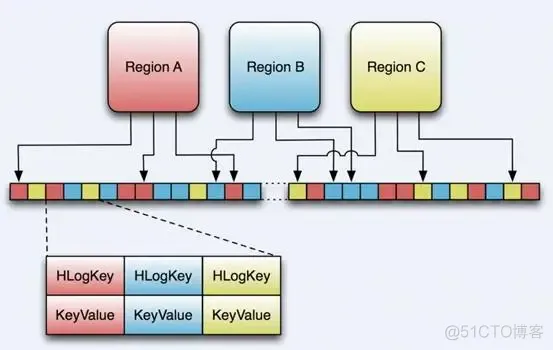
引入HLog原因:
在分布式系统环境中,无法避免系统出错或者宕机,一旦HRegionServer意外退出,MemStore中的内存数据就会丢失,引入HLog就是防止这种情况 。
工作机制:
每个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,每次用户操作写入Memstore的同时,也会写一份数据到HLog文件,HLog文件定期会滚动出新,并删除旧的文件(已持久化到StoreFile中的数据)。当HRegionServer意外终止后,HMaster会通过Zookeeper感知,HMaster首先处理遗留的HLog文件,将不同region的log数据拆分,分别放到相应region目录下,然后再将失效的region重新分配,领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复。
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,格式主要有两种:
1 HFile HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile ;
2 HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File;
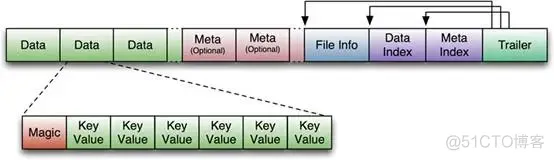
HFile里面的每个KeyValue对就是一个简单的byte数组。这个byte数组里面包含了很多项,并且有固定的结构。

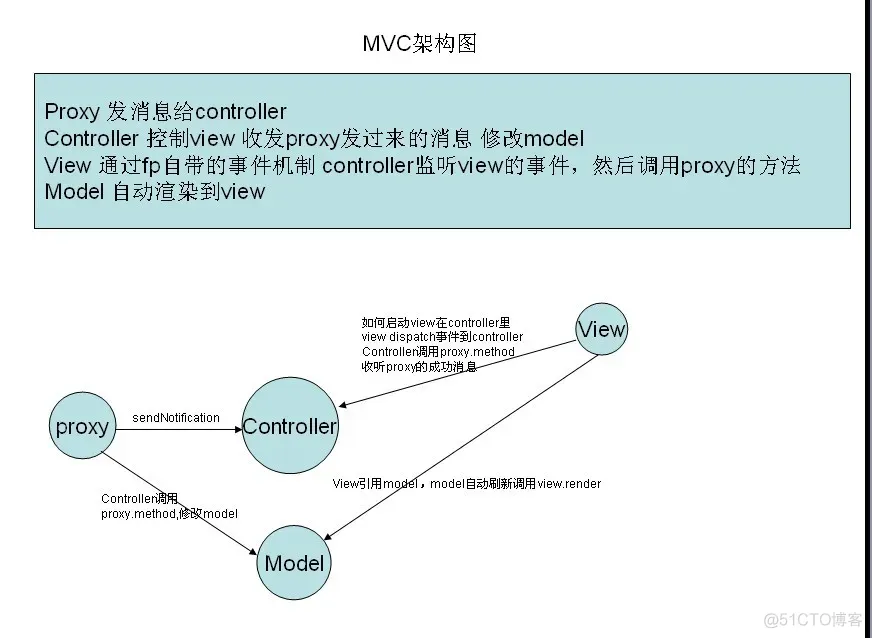
模块与模块之间的通信也通过sendNotifcation发送消息。
用一张图分析了Google给出的MVP架构,但是在Google给出的所有案例里面除了基本的MVP架构还有其它几种架构,今天就来分析其中的Clean架构。同样的,网上介绍Clean架构的文章很多,我也就不用文字过多叙述了,还是用一张类图来分析一下Clean架构的这个案例吧。好了,先直接上图!
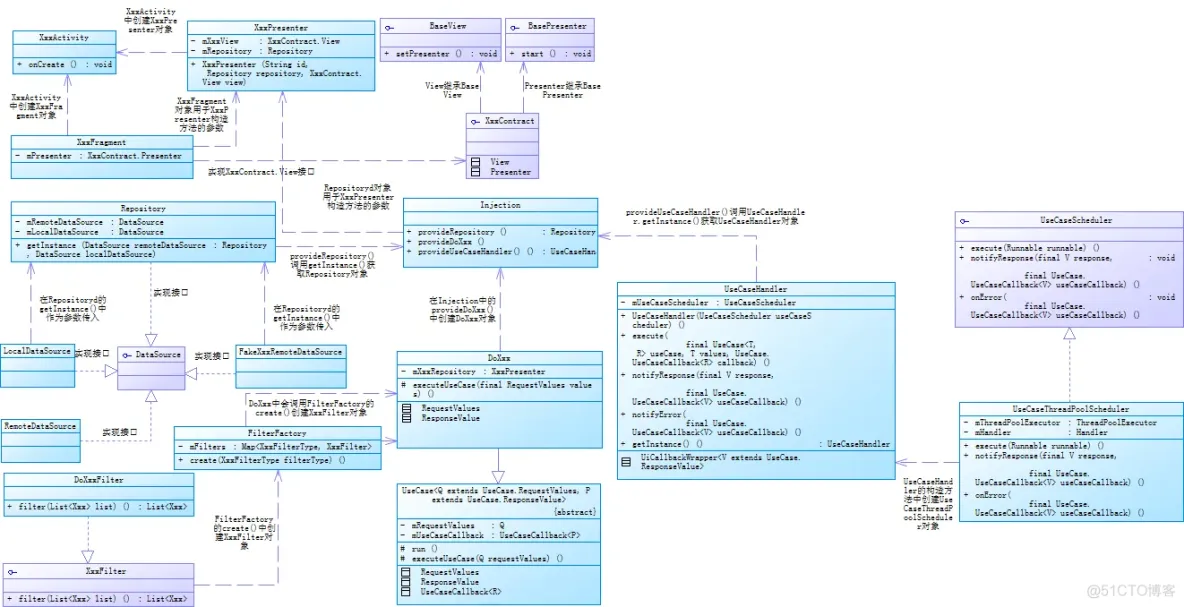
上完图,再说一说我对Clean架构的一个理解吧。
对比前一篇文章的MVP架构图可以看出,clean在一定程度上继承了mvp的设计思想,但是其抽象程度比mvp更高。
初次看这个demo的时候,确实被震撼了一下——原来可以这样写代码!!!
跟之前用的一些项目框架和我自己平时写的一些代码对比一下,只能感叹clean的这种设计思想真不是一般的程序员可以想出来的。
它对接口、抽象类和实现类之间的实现、继承、调用关系发挥到了一个比较高的层次,它并不是像我们平时写代码那样很直白地写下来,而是充分利用了面向对象的封装性、继承性和多态性,是对面向对象思想的一个高度理解。
其实,要说clean复杂,它确实有些难理解,可是如果你真的理解了面向对象思想,那么又会觉得这样的设计完全在情理之中。
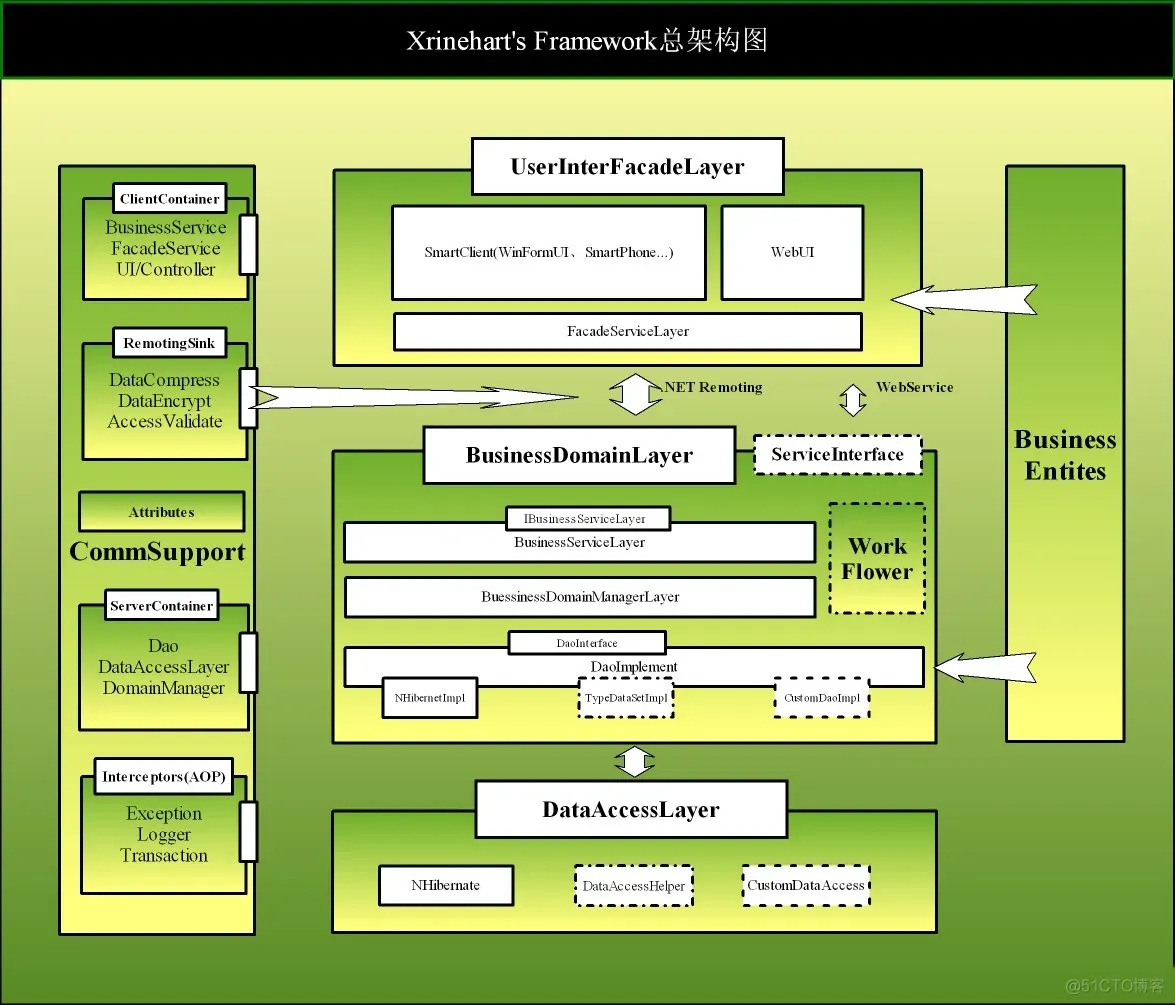
这个框架用到了一些.NET社区比较前沿的技术,比如ORM, IOC容器, AOP拦截等,在.NET 2.0的基础上构建了一个.NET Remoting的分布式开发框架。
项目开发最关注的就是开发效率,其次是项目的可管理可控性,最后是架构的可扩展性。我希望在我的框架设计中能够将这三者很好的整合在一起。
大致的思路是:
1、可扩展性:通过IOC容器的使用降低项目中各个模块之间的依赖性;用领域模式来设计业务核心层,降低业务层对数据层和界面层的耦合度;分布式选择Remoting为主,可以再包装为WebService或者直接发布为WebService。
2、将敏捷的项目管理思路引入到框架中,框架充分支持TDD测试驱动和运行日志驱动,为敏捷管理提供技术支持。
3、初步通过AOP技术减少和核心业务无关的系统级代码:如事务处理、异常处理、日志记录等;并在将来为架构提供可视化的代码配置生成工具,以最快的速度构建项目的主体结构,并尽可能大的增大灵活性。
主架构图:
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















