















































软件

产品


1、准备一个需要的模型(如:inception),然后确定算法的框架,初始化参数都是随机的,准备数据集,从头开始训练。
2、准备一个已经训练好的模型(如:inception),因为已经训练好,所以卷积层、池化层里面的权值和参数不需要更改,需要更改的只是最后一层,分类的地方。
3、准备一个已经训练好的模型,同方法二不一样的地方是,卷积层和池化层的权值和参数也参与训练,但是学习率很低,只是一个微调。
先从TensorFlow的GitHub上将TensorFlow下载下来

我们要用到的是:tensorflow-r1.8\tensorflow\examples\image_retraining中的retrain.py文件
准备数据集
数据集存放路径:E:\anaconda\test1\9_1\data

最后测试结果的图片放在:E:\anaconda\test1\9_1\images中
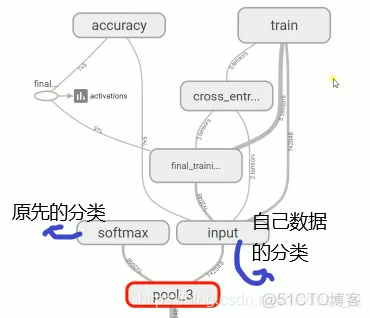
因为我们不改变前面卷积层和池化层的操作,所以我们训练的图片(图片1)经过前面的神经网络传到倒数第二层:
在pool3中得到date1,然后我们训练神经网络最后一层,用到的输入值不是我们原始的数据,而是处理过得date1
具体步骤:
1、编辑retrain.bat文件

–bottleneck_dir bottleneck ^是保存的pool3的data的数据,文件夹在E:\anaconda\test1\9_1中
–how_many_training_steps 50 ^ 是训练周期
–model_dir E:\anaconda\test1\inception_model/ ^ 是模型的文件
–output_graph output_graph.pb ^ 是输出模型,在当前路径下
–output_labels output_labels.txt ^ 是输出的目录
–image_dir data/ 是要分类的图片
(注:该文件目录名称不能有大写或者空格)
(如果图片没有更改,要重新运行文件,则在当前盘下tmp中的文件删掉)
2、双击运行retrain.bat
具体代码如下:
import tensorflow as tf
import os
import numpy as np
import re
from PIL import Image
import matplotlib.pyplot as plt
lines = tf.gfile.GFile('output_labels.txt').readlines()
uid_to_human = {}
#一行一行读取数据
for uid,line in enumerate(lines) :
#去掉换行符
line=line.strip('\n')
uid_to_human[uid] = line
def id_to_string(node_id):
if node_id not in uid_to_human:
return ''
return uid_to_human[node_id]
#创建一个图来存放google训练好的模型
with tf.gfile.FastGFile('output_graph.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('final_result:0')
#遍历目录
for root,dirs,files in os.walk('images/'):
for file in files:
#载入图片
image_data = tf.gfile.FastGFile(os.path.join(root,file), 'rb').read()
predictions = sess.run(softmax_tensor,
{'DecodeJpeg/contents:0': image_data})#图片格式是jpg格式
predictions = np.squeeze(predictions)#把结果转为1维数据
#打印图片路径及名称
image_path = os.path.join(root,file)
print(image_path)
#显示图片
img=Image.open(image_path)
plt.imshow(img)
plt.axis('off')
plt.show()
#排序
top_k = predictions.argsort()[::-1]
print(top_k)
for node_id in top_k:
#获取分类名称
human_string = id_to_string(node_id)
#获取该分类的置信度
score = predictions[node_id]
print('%s (score = %.5f)' % (human_string, score))
print()
运行结果为:

代码:把图片的数据装换成tfrecord后缀的文件。
import tensorflow as tf
import os
import random
import math
import sys
#验证集数量
_NUM_TEST = 500
#随机种子
_RANDOM_SEED = 0
#数据块
_NUM_SHARDS = 5
#数据集路径
DATASET_DIR = "E:/anaconda/test1/9_2/slim/images/"
#标签文件名字
LABELS_FILENAME = "E:/anaconda/test1/9_2/slim/images/labels.txt"
#定义tfrecord文件的路径+名字
def _get_dataset_filename(dataset_dir, split_name, shard_id):
output_filename = 'image_%s_%05d-of-%05d.tfrecord' % (split_name, shard_id, _NUM_SHARDS)
return os.path.join(dataset_dir, output_filename)
#判断tfrecord文件是否存在
def _dataset_exists(dataset_dir):
for split_name in ['train', 'test']:
for shard_id in range(_NUM_SHARDS):
#定义tfrecord文件的路径+名字
output_filename = _get_dataset_filename(dataset_dir, split_name, shard_id)
if not tf.gfile.Exists(output_filename):
return False
return True
#获取所有文件以及分类
def _get_filenames_and_classes(dataset_dir):
#数据目录(路径)
directories = []
#分类名称(文件名)
class_names = []
for filename in os.listdir(dataset_dir):
#合并文件路径
path = os.path.join(dataset_dir, filename)
#判断该路径是否为目录
if os.path.isdir(path):
#加入数据目录
directories.append(path)
#加入类别名称
class_names.append(filename)
photo_filenames = []
#循环每个分类的文件夹
for directory in directories:
for filename in os.listdir(directory):
path = os.path.join(directory, filename)
#把图片加入图片列表
photo_filenames.append(path)
####返回每个图片的路径和分类名字
return photo_filenames, class_names
def int64_feature(values):
if not isinstance(values, (tuple, list)):
values = [values]
return tf.train.Feature(int64_list=tf.train.Int64List(value=values))
def bytes_feature(values):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[values]))
def image_to_tfexample(image_data, image_format, class_id):
#Abstract base class for protocol messages.
return tf.train.Example(features=tf.train.Features(feature={
'image/encoded': bytes_feature(image_data),
'image/format': bytes_feature(image_format),
'image/class/label': int64_feature(class_id),
}))
def write_label_file(labels_to_class_names, dataset_dir,filename=LABELS_FILENAME):
labels_filename = os.path.join(dataset_dir, filename)
with tf.gfile.Open(labels_filename, 'w') as f:
for label in labels_to_class_names:
class_name = labels_to_class_names[label]
f.write('%d:%s\n' % (label, class_name))
#把数据转为TFRecord格式
def _convert_dataset(split_name, filenames, class_names_to_ids, dataset_dir):
assert split_name in ['train', 'test']
#计算每个数据块有多少数据
#将测试集和训练集分别分块(分_NUM_SHARDS块)
num_per_shard = int(len(filenames) / _NUM_SHARDS)
with tf.Graph().as_default():
with tf.Session() as sess:
for shard_id in range(_NUM_SHARDS):
#定义tfrecord文件的路径+名字
output_filename = _get_dataset_filename(dataset_dir, split_name, shard_id)
with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer:
#每一个数据块开始的位置
start_ndx = shard_id * num_per_shard
#每一个数据块最后的位置
end_ndx = min((shard_id+1) * num_per_shard, len(filenames))
for i in range(start_ndx, end_ndx):
try:
sys.stdout.write('\r>> Converting image %d/%d shard %d' % (i+1, len(filenames),
shard_id))
sys.stdout.flush()
#读取图片
image_data = tf.gfile.FastGFile(filenames[i], 'rb').read()
#获得图片的类别名称
class_name = os.path.basename(os.path.dirname(filenames[i]))
####os.path.dirname去掉文件名,返回目录
#####例:print(os.path.dirname("E:/Read_File/read_yaml.py"))
#########结果:E:/Read_File
####os.path.basename返回path最后的文件名
#找到类别名称对应的id
class_id = class_names_to_ids[class_name]
#生成tfrecord文件
example = image_to_tfexample(image_data, b'jpg', class_id)
tfrecord_writer.write(example.SerializeToString())
except IOError as e:
print("Could not read:",filenames[i])
print("Error:",e)
print("Skip it\n")
sys.stdout.write('\n')
sys.stdout.flush()
if __name__ == '__main__':
#判断tfrecord文件是否存在
if _dataset_exists(DATASET_DIR):
print('tfcecord文件已存在')
else:
#获得所有图片以及分类
photo_filenames, class_names = _get_filenames_and_classes(DATASET_DIR)
#把分类转为字典格式,类似于{'house': 3, 'flower': 1, 'plane': 4, 'guitar': 2, 'animal': 0}
class_names_to_ids = dict(zip(class_names, range(len(class_names))))
#把数据切分为训练集和测试集
random.seed(_RANDOM_SEED)
random.shuffle(photo_filenames)
training_filenames = photo_filenames[_NUM_TEST:]
testing_filenames = photo_filenames[:_NUM_TEST]
#数据转换
_convert_dataset('train', training_filenames, class_names_to_ids, DATASET_DIR)
_convert_dataset('test', testing_filenames, class_names_to_ids, DATASET_DIR)
#输出labels文件
labels_to_class_names = dict(zip(range(len(class_names)), class_names))
write_label_file(labels_to_class_names, DATASET_DIR)
结果为:
Converting image 2180/2181 shard 4 Converting image 500/500 shard 4
在slim文件夹下面的datasets中(本代码是在E:\anaconda\test1\9_2\slim\datasets)打开dataset_factory.py如下:

在datasets_map中添加和from datasets import myimage’myimage’:myimage, 添加完成如下:

同样在E:\anaconda\test1\9_2\slim\datasets中,新建myimage.py文件
内容如下:
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Provides data for the flowers dataset.
The dataset scripts used to create the dataset can be found at:
tensorflow/models/slim/datasets/download_and_convert_flowers.py
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import tensorflow as tf
from datasets import dataset_utils
slim = tf.contrib.slim
_FILE_PATTERN = 'image_%s_*.tfrecord'
SPLITS_TO_SIZES = {'train': 1000, 'test': 500}
_NUM_CLASSES = 5
_ITEMS_TO_DESCRIPTIONS = {
'image': 'A color image of varying size.',
'label': 'A single integer between 0 and 4',
}
def get_split(split_name, dataset_dir, file_pattern=None, reader=None):
"""Gets a dataset tuple with instructions for reading flowers.
Args:
split_name: A train/validation split name.
dataset_dir: The base directory of the dataset sources.
file_pattern: The file pattern to use when matching the dataset sources.
It is assumed that the pattern contains a '%s' string so that the split
name can be inserted.
reader: The TensorFlow reader type.
Returns:
A `Dataset` namedtuple.
Raises:
ValueError: if `split_name` is not a valid train/validation split.
"""
if split_name not in SPLITS_TO_SIZES:
raise ValueError('split name %s was not recognized.' % split_name)
if not file_pattern:
file_pattern = _FILE_PATTERN
file_pattern = os.path.join(dataset_dir, file_pattern % split_name)
# Allowing None in the signature so that dataset_factory can use the default.
if reader is None:
reader = tf.TFRecordReader
keys_to_features = {
'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
'image/format': tf.FixedLenFeature((), tf.string, default_value='png'),
'image/class/label': tf.FixedLenFeature(
[], tf.int64, default_value=tf.zeros([], dtype=tf.int64)),
}
items_to_handlers = {
'image': slim.tfexample_decoder.Image(),
'label': slim.tfexample_decoder.Tensor('image/class/label'),
}
decoder = slim.tfexample_decoder.TFExampleDecoder(
keys_to_features, items_to_handlers)
labels_to_names = None
if dataset_utils.has_labels(dataset_dir):
labels_to_names = dataset_utils.read_label_file(dataset_dir)
return slim.dataset.Dataset(
data_sources=file_pattern,
reader=reader,
decoder=decoder,
num_samples=SPLITS_TO_SIZES[split_name],
items_to_descriptions=_ITEMS_TO_DESCRIPTIONS,
num_classes=_NUM_CLASSES,
labels_to_names=labels_to_names)
在slim目录下,添加train.bat
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















