















































软件

产品


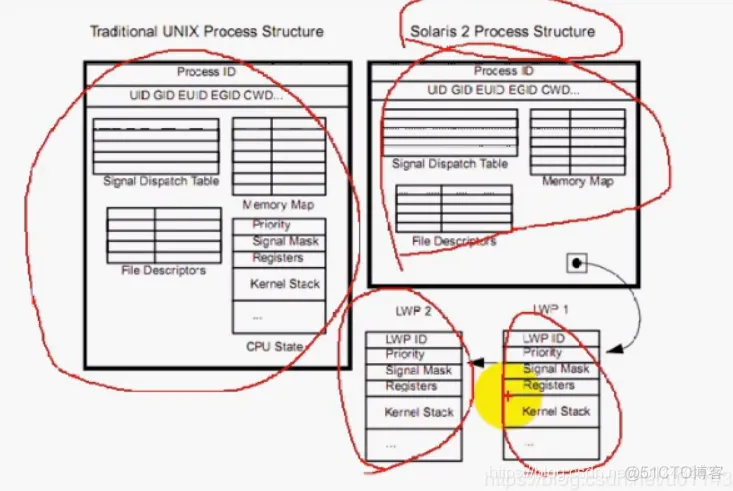
更准确的定义是:线程是一个进程内部的控制序列(指令序列)
1)程序: 完成特定功能的一系列有序指令的集合,通过编译链接成可执行文件:
2)可执行文件: 称之为程序,代码段(指令)+数据段(指令操作的程序),保存在磁盘上
3)进程: 程序的一次动态执行过程,代码段+数据段+堆栈段+PCB(进程控制块:进程运行状态(包括:就绪状态,运行状态,等待状态),进程上下文,进程执行的CPU状态,当前运行到哪个地址:IP指令指针+SP堆栈指针+寄存器状态)
| 进程 | 程序 |
| 动态的(在不断的推进的过程中,会更改数据段,产生一些临时的数据保存在堆栈段当中,且PCB的的状态也是不断发生改变的) | 静态的(保存在磁盘上,程序文件信息是不会改变的) |
| 短暂的(只是程序的一次动态执行过程) | 永久的 |
| 代码段+数据段+堆栈段+PCB | 代码段+数据段 |
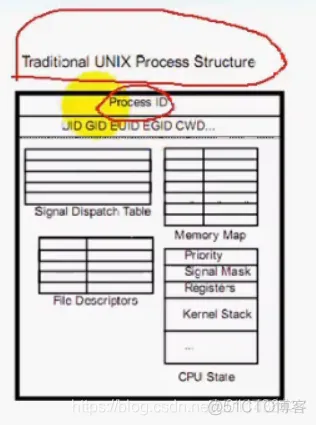
1)线程ID
2)一组寄存器:IP指令指针+SP堆栈指针+通用寄存器等
3)栈:线程的局部变量
4)errno:每个线程都有一个errno
5)信号状态:每个线程都有一个对信号的处理状态
6)优先级
1)当一个进程执行一个fork调用的时候,会创建出进程的一个新拷贝,新进程将拥有它自己的变量和它自己的PID。这个新进程的运行时间是独立的,他在执行时,几乎完全独立于创建他的进程
2)在进程里面创建一个新线程的时候,新的执行线程会拥有自己的堆栈(因此,也就拥有自己的局部变量),但要与他的创建者共享全局变量,文件描述符,信号处理器和当前的工作目录状态
1)创建一个新线程的代价要比创建一个新进程小得多
2)与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少得多
3)线程占用的资源要比进程少很多
4)能充分利用多处理器的可并行数量,eg:一个进程若有2个线程构成,则这2个线程可能竞争到2个CPU
5)在等待慢速I/O操作结束的同时,程序可执行其它的计算任务
6)计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
7)I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
eg:密集:一个线程可以等待多个不同的IO,I/O密集型占用IO,可以让出CPU
1)性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享一个处理器。
如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
2)健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成的不良影响的可能性是很大的,换句话说是线程之间是缺乏保护的
3)缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。(一个进程不会随意破坏其它进程的地址空间,因为他受到内存管理单元MMU的保护)
5)编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
1)操作系统提供了各种模型,用来调度应用程序创建的线程。这些模型之间的主要不同是:在竞争系统资源(特别是CPU时间)时,线程调度竞争范围(thread-schedulingcontention scope)不一样。
2)进程竞争范围(process contention scope):各个线程在同一个进程竞争被调度的CPU时间(但不直接和其它进程中的线程竞争)
3)系统竞争范围(system contention scope):线程直接和系统范围内的其它线程竞争
1)N:1用户线程模型
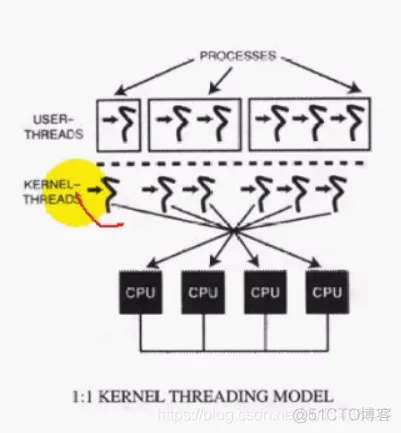
2)1:1核心线程模型
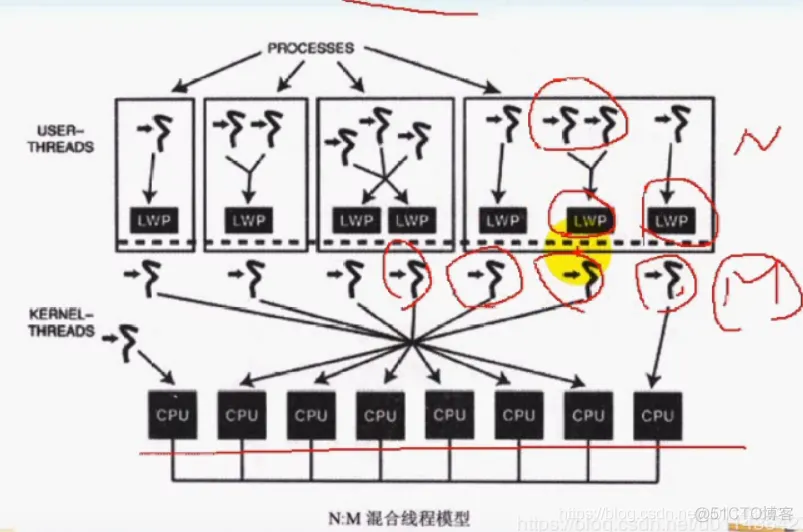
3)N:M混合线程模型
1)KERNEL THREADS:实际上就是进程,系统中并未提供线程的支持 USER THREADS:表示线程 只要一个线程阻塞了,另外一个线程也不能工作了
2)线程实现 建立在进程控制进制之上,由用户空间的程序库来管理。OS内核完全不知道线程信息,这些线程称之为用户空间线程
3)这些线程都工作在进程竞争范围
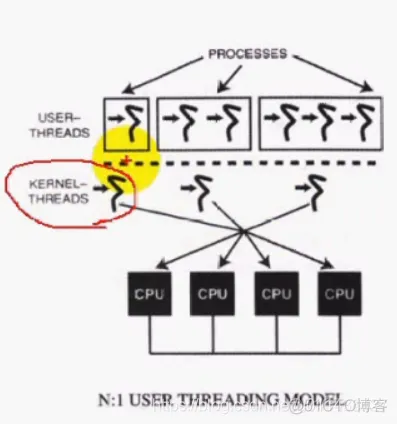
1)在N:1线程模型中,内核不干涉线程的任何声明活动,也不干涉同一进程中的线程环境切换
2)在N:1线程模型中,一个进程中的多个线程只能调度到一个CPU,这种约束限制了可用的并行总量
3)第一个缺点是如果某个线程执行了一个阻塞式操作(read),那么,进程中的所有线程都会阻塞,直到那个操作结束。
为此,一些线程的实现是为这些阻塞式函数提供包装器,用作非阻塞版本替换这些系统调用,以消除这种限制。
1)操作系统对线程开始支持了USER THREADS的2个用户线程,对应KERNEL THREADS核心的2个线程,这2个线程可以调度到2个CPU
2)在1:1核心线程模型中,应用程序创建的每一个线程都由一个核心线程直接管理
3)OS内核将每一个核心线程都调用在系统CPU上,因此,所有线程都工作在系统竞争范围
4)这种线程的创建与调度由内核完成,因为这种线程的系统开销比较大(但一般来讲,比进程开销小)
N:M混合线程模型提供了两级控制,将用户线程映射为系统的可调度体以实现并行,这个可调度体称为轻量级进程LWP(lightweighr process),LWP再一一映射到核心线程
1)结合了1:1和N:1线程的优势,因为轻量级进程LWP比核心线程的切换开销小,所以用户线程的切换开销更小,另外也充分利用了多核处理器的功能,因为轻量级进程可以调度到核心线程KERNEL THREAD,每个核心线程可以调度到CPU,因为可以充分利用到多核的功能;
2)当前的POSIX 线程就是N:M混合线程实现的
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















