















































软件

产品


ONNX Runtime:由微软推出,用于优化和加速机器学习推理和训练,适用于ONNX模型,是一个跨平台推理和训练机器学习加速器(ONNX Runtime is a cross-platform inference and training machine-learning accelerator),源码地址:https://github.com/microsoft/onnxruntime,最新发布版本为v1.11.1,License为MIT:
1.ONNX Runtime Inferencing:高性能推理引擎
(1).可在不同的操作系统上运行,包括Windows、Linux、Mac、Android、iOS等;
(2).可利用硬件增加性能,包括CUDA、TensorRT、DirectML、OpenVINO等;
(3).支持PyTorch、TensorFlow等深度学习框架的模型,需先调用相应接口转换为ONNX模型;
(4).在Python中训练,确可部署到C++/Java等应用程序中。
2.ONNX Runtime Training:于2021年4月发布,可加快PyTorch对模型训练,可通过CUDA加速,目前多用于Linux平台。
通过conda命令安装执行:
conda install -c conda-forge onnxruntime以下为测试代码:通过ResNet-50对图像进行分类
import numpy as npimport onnxruntimeimport onnxfrom onnx import numpy_helperimport urllib.requestimport osimport tarfileimport jsonimport cv2 # reference: https://github.com/onnx/onnx-docker/blob/master/onnx-ecosystem/inference_demos/resnet50_modelzoo_onnxruntime_inference.ipynbdef download_onnx_model(): labels_file_name = "imagenet-simple-labels.json" model_tar_name = "resnet50v2.tar.gz" model_directory_name = "resnet50v2" if os.path.exists(model_tar_name) and os.path.exists(labels_file_name): print("files exist, don't need to download") else: print("files don't exist, need to download ...") onnx_model_url = "https://s3.amazonaws.com/onnx-model-zoo/resnet/resnet50v2/resnet50v2.tar.gz" imagenet_labels_url = "https://raw.githubusercontent.com/anishathalye/imagenet-simple-labels/master/imagenet-simple-labels.json" # retrieve our model from the ONNX model zoo urllib.request.urlretrieve(onnx_model_url, filename=model_tar_name) urllib.request.urlretrieve(imagenet_labels_url, filename=labels_file_name) print("download completed, start decompress ...") file = tarfile.open(model_tar_name) file.extractall("./") file.close() return model_directory_name, labels_file_name def load_labels(path): with open(path) as f: data = json.load(f) return np.asarray(data) def images_preprocess(images_path, images_name): input_data = [] for name in images_name: img = cv2.imread(images_path + name) img = cv2.resize(img, (224, 224)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) data = np.array(img).transpose(2, 0, 1) #print(f"name: {name}, opencv image shape(h,w,c): {img.shape}, transpose shape(c,h,w): {data.shape}") # convert the input data into the float32 input data = data.astype('float32') # normalize mean_vec = np.array([0.485, 0.456, 0.406]) stddev_vec = np.array([0.229, 0.224, 0.225]) norm_data = np.zeros(data.shape).astype('float32') for i in range(data.shape[0]): norm_data[i,:,:] = (data[i,:,:]/255 - mean_vec[i]) / stddev_vec[i] # add batch channel norm_data = norm_data.reshape(1, 3, 224, 224).astype('float32') input_data.append(norm_data) return input_data def softmax(x): x = x.reshape(-1) e_x = np.exp(x - np.max(x)) return e_x / e_x.sum(axis=0) def postprocess(result): return softmax(np.array(result)).tolist() def inference(onnx_model, labels, input_data, images_name, images_label): session = onnxruntime.InferenceSession(onnx_model, None) # get the name of the first input of the model input_name = session.get_inputs()[0].name count = 0 for data in input_data: print(f"{count+1}. image name: {images_name[count]}, actual value: {images_label[count]}") count += 1 raw_result = session.run([], {input_name: data}) res = postprocess(raw_result) idx = np.argmax(res) print(f" result: idx: {idx}, label: {labels[idx]}, percentage: {round(res[idx]*100, 4)}%") sort_idx = np.flip(np.squeeze(np.argsort(res))) print(" top 5 labels are:", labels[sort_idx[:5]]) def main(): model_directory_name, labels_file_name = download_onnx_model() labels = load_labels(labels_file_name) print("the number of categories is:", len(labels)) # 1000 images_path = "../../data/image/" images_name = ["5.jpg", "6.jpg", "7.jpg", "8.jpg", "9.jpg", "10.jpg"] images_label = ["goldfish", "hen", "ostrich", "crocodile", "goose", "sheep"] if len(images_name) != len(images_label): print("Error: images count and labes'length don't match") return input_data = images_preprocess(images_path, images_name) onnx_model = model_directory_name + "/resnet50v2.onnx" inference(onnx_model, labels, input_data, images_name, images_label) print("test finish") if __name__ == "__main__": main()测试图像如下所示:

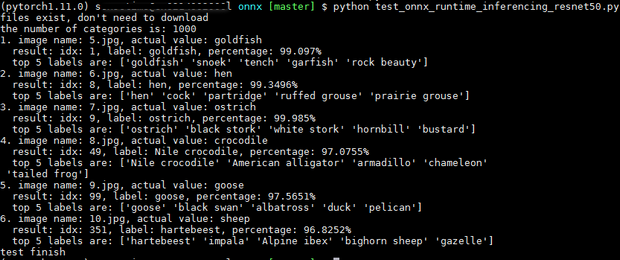
执行结果如下所示:
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















