















































软件

产品


对于用户而言,可以且有价值的 Abaqus 二次开发主要有两种,求解器层次的 Fortran 和 前后处理层次的 Python 。前者对应用户子程序开发,后者对应用户图形界面程序开发。;Abaqus 用户子程序开发基于 Fortran 语言,用户可以根据实际需求编写材料本构关系 (UMAT/VUMAT)、自定义单元 UEL 等。
用户图形界面开发则基于 Python 语言,主要是根据需求对原有 Abaqus/CAE 功能组件进行扩展,开发专用的前后处理模块及 GUI 工具等。用户子程序的开发影响的是 CAE 分析过程中的求解环节,GUI 开发主要是方便用户根据自身的需求开发前后处理工具或者辅助用户实现参数化的建模及数据处理等工作,其影响的是 CAE 分析过程中的前后处理环节。
大量可重复建模工作适合以二次开发方式实现,其余没必要,老老实实点软件。本文 Abaqus 版本: 6.14-1 。
三角函数的计算
def cos(x):
# 功能:计算x的余弦值
# 参数:x为角度,单位为度
# 返回:余弦值
import math
pi = math.pi
x = x * pi / 180
cosine = math.cos(x)
return cosine
def sin(x):
# 功能:计算x的正弦值
# 参数:x为角度,单位为度
# 返回:余弦值
import math
pi = math.pi
x = x * pi / 180
sine = math.sin(x)
return sine

Abaqus分析流程
建立的 Abaqus 模型通常包括如下信息:几何形状、单元局部特性、材料数据、荷载和边界条件、分析类型、输出要求等。
建模的过程是把待分析问题的模型图形化的过程,建模的最终目的是生成一个 Abaqus 求解器能识别的输入文件即 inp 文件。
inp 文件不是编程语言,只是按照 Abaqus 求解器的计算要求,而形成的输入文件。
Abaqus 输入文件是前处理 (Abaqus/Pre) 和求解器 (Abaqus/Standard) 之间的交流工具,它包含了对分析模型的完整描述。
模拟计算即选择适当的求解器求解 inp 文件所确定的数值问题,求解器的求解过程实际上就是求解大型偏微分方程组的过程。
计算速度(解方程的速度)和计算精度是评价有限元软件性能的两个重要方面。
Abaqus/Standard 和 Abaqus/Explicit 就是用来求解大型方程组的求解器。
- Abaqus/Standard 通用分析模块/隐式分析求解器,能够求解线性和非线性问题,包括静力、动力、热和电问题等的响应。
- Abaqus/Explicit 特殊分析模块/显示分析求解器,采用显式动力有限元列式,适用于冲击、爆炸等短暂、瞬时的动态事件的分析。
后处理一般是由 Abaqus/Post 或其他后处理程序实现的,Abaqus/Post 读入二进制文件,可以用各种各样方式显示结果,如彩色等值线图、动画、应力云图、位移云图及x-y平面绘图等。求解器计算求解后的分析结果主要存储在 .odb, .dat, .res, .fil 文件中。
前处理的最终目的是生成 .inp 文件,求解器根据 inp 文件的有关要求进行求解计算并输出计算结果,后处理根据输出的结果 (.odb文件) 进行数据的二次加工供工程人员参考。前处理及后处理用户起主导作用,计算任务提交后计算机自动完成模拟计算。
为了实现某个功能,用户需在特定的 GUI (图形界面) 中输入相关参数,点击 “OK” 或 “Continue” 按钮后,程序后台将输入参数打包并生成与实现该功能相对应的 Python 语句,该语句会进一步传递给 Kernel 执行,这就是这个实现这个功能的完整流程。
这一条条 Python 语句,就是要发送给内核执行的一条条命令。
在 Abaqus 功能实现的过程中,后台程序实时记录用户在 Abaqus/CAE 中各种操作所对应的 Python 语句,并将其记录在当前工作目录下的 abaqus.rpy 文件中,abaqus.rpy 文件是实时更新的,也就是说,在 Abaqus/CAE 中,每完成一步操作,它所对应的 Python 语句都会立即出现在 abaqus.rpy 文件中,用户可以用任何一款文本编剧软件打开 abaqus.rpy 文件,查看操作对应的 Python 语句,并根据自身需要进行修改,这就为 Abaqus 的二次开发提供了很大的便利,只要用户能够在 Abaqus/CAE 中实现某一功能,那么它所对应的 Python 语句可直接查看 abaqus.rpy 文件得到,而不需要在帮助文档中查找,这就大大降低了二次开发的难度。
Abaqus/CAE records its commands as a Python script in the replay (.rpy) file.
当你开发一些自定义的功能时,通常开始于创建实现这些功能的内核命令 (Python语句) 。这些命令可以通过在 Abaqus /CAE 中命令行接口 (CLI) 中执行来进行调试。一旦从 CLI 中确定内核命令可以准确运行,那么你就可以设计图形用户界面 (GUI) 来收集内核命令所需要的用户输入。
.rpy 文件一般位于 “当前工作目录” 或 “current work directory” 中,一般命名为 abaqus.rpy 。
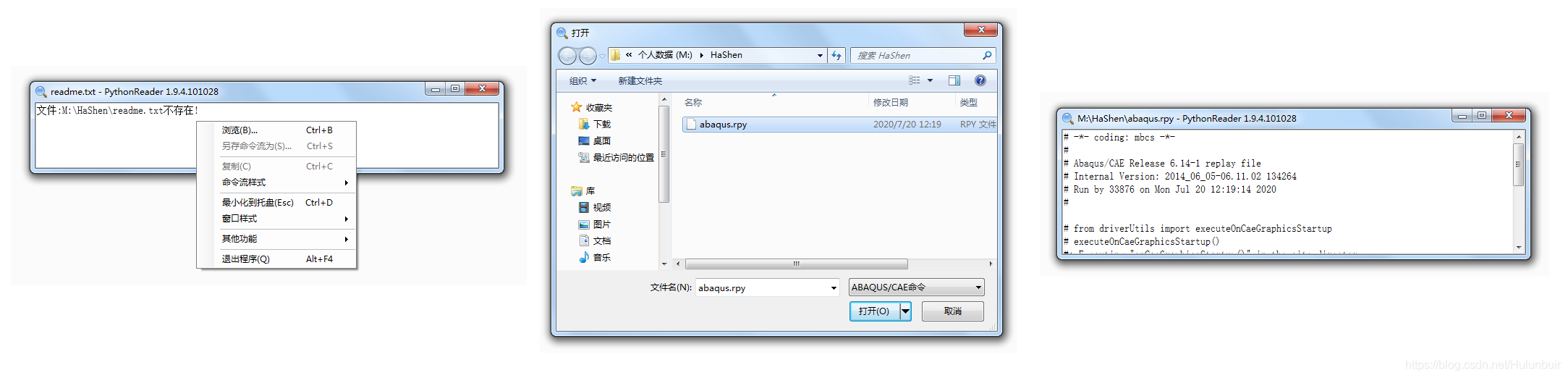
PythonReader 软件类似于一个文本查看器,它小巧精炼,以浮动窗口的形式把 rpy 文件的内容显示在当前窗口,使用者可以边操作边学习,非常方便高效。PythonReader 可从 Simwe 论坛 Abaqus 板面内搜索获得。ABAQUS PythonReader 最新版本:1.9.4.101028 .
Step 1. 设置 Abaqus/CAE 的当前工作目录为 M:HaShen 。

Step 2. 启动 Abaqus/CAE,M:HaShen 目录内同步出现 abaqus.rpy 文件。

Step 3. 启动 PythonReader,鼠标右键进行配置。

勾选可调整大小的边框
Step 4. 启动 PythonReader,匹配 abaqus.rpy 文件。
有限元软件中未明确具体的单位制,但应保证各单位间协调统一,常用的单位制如下:
| 质量 | 长度 | 时间 | 力 | 压强/应力 | 能量 | 密度 | 弹性模量 |
|---|---|---|---|---|---|---|---|
| kg | m | s | N | Pa | J | kg/m3 | Pa |
| t | mm | s | N | MPa | N-mm | t/mm3 | MPa |
1 k g / m 3 = 1 0 − 12 t / m m 3 1 kg/m^3 = 10^{-12} t/mm^3 1kg/m3=10−12t/mm3
为了使二次开发编写的 Python 代码逻辑清晰、易读易解,现对主要变量的命名进行约定,见以下各表。该命名规则为个人习惯,非强制要求。
| 缩写 | 全拼 | 含义 | 示例 |
|---|---|---|---|
| iges | - | iges 文件 | |
| pre | prefix | 名称前缀 | |
| post | postfix | 名称后缀 | 几何(部件)/装配/部件实例 |
| 缩写 | 全拼 | 含义 | 示例 |
|---|---|---|---|
| vp | viewport | 视口 | |
| mymdb/currmdb | my model database | 当前引用模型数据库 | |
| iges | - | iges 文件 | |
| skh | sketch | 草图 | |
| prt | part | 部件 | |
| v | vertex | 几何点 | |
| e | edge | 几何边 | |
| s/surf | surface geometry | 几何面 | |
| c | cell | 几何体 | 特征 |
| 缩写 | 全拼 | 含义 | 示例 |
|---|---|---|---|
| dtm | datum | ||
| pl | datum plane | 基准面/参考面 | 材性 |
| 缩写/前缀 | 全拼 | 含义 | 示例 |
|---|---|---|---|
| mat | material | 材料 | |
| E/e | Young’s modulus | 杨氏模量 | |
| nu | Poisson ratio | 泊松比 | |
| rho | Density | 质量密度 | |
| Abq-1D-Sec- | 1D section | 梁截面 | |
| Abq-2D-Sec- | 2D section | 板壳截面 | |
| Abq-3D-Sec- | 3D section | 实体截面 |
阿拉伯数字为一级排序,英文字母为二级排序,如 1A、1B、1C、2、3A、3B 等,反之亦可。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
=============================
Python Version: 2.7.3
Abaqus/CAE 6.14-1
Email: liyang@alu.hit.edu.cn
=============================
"""
from abaqus import *
from abaqusConstants import *
from caeModules import *
from driverUtils import executeOnCaeStartup
import regionToolset
import os
Abaqus 建模过程中,如荷载时程等数据需由外部文件获得。因此,有必要了解一些简单的关于文件获取的函数,如文本文件中数据的读取,文件名的获取等。
def get_file_name(dir, ext, pre=None, post=None, remove=True):
"""获取某一文件夹下符合指定拓展名的全部文件名,并根据需求去掉文件名的前后缀。
:param dir: 文件夹路径。
:param ext: 文件拓展名,函数根据该拓展名筛选文件。
:param pre: 文件名前缀,若为None,则获取dir文件夹内全部符合给定拓展名要求的文件名。
:param post: 文件名后缀,暂时不按后缀筛选文件名也没必要。
:param remove: 去掉文件名前后缀选项,若为True,则去掉前后缀。
返回值names为去掉前后缀的文件名列表
"""
names = []
for root, dirs, files in os.walk(top=dir):
tempfnames = files
break
# break保证dir目录内所包含的子目录中的文件名不被迭代。
for fname in tempfnames:
# 根据给定拓展名筛选文件名
extension = os.path.splitext(fname)[1]
if extension == ext:
print(fname)
names.append(fname)
if pre is not None:
# 根据给定前缀名称筛选文件名
tempfnames = []
for fname in names:
l = len(pre)
if fname[:l] == pre:
tempfnames.append(fname)
names = tempfnames
if remove is True:
tempnames = []
for fname in names:
if pre is not None:
l = len(pre)
fname = fname[l:]
if post is not None:
r = len(post)
fname = fname[:-r]
tempnames.append(fname)
names = tempnames
names = sorted(names) # 排序
return names
获取 E:AbqTest empLoads 文件目录内,拓展名为 .txt 文件的文件名,文件名称去掉前缀 CRSTIII_160_80Hz_ 及后缀 .txt,remove 设置为 True,返回值 names = [“0.12207”,“0.18311”,. . .],若 remove = False,则忽略 pre 及 post 的设置,函数返回值为由文件全名构成的列表。
directory = r"E:AbqTest empLoads"
names = get_file_name(dir=directory, ext=".txt", pre="CRSTIII_160_80Hz_", post=".txt")
# 获取E:AbqTest empLoads文件夹内所有txt文件的文件名,并去掉前后缀。
print(names)
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















