





































































昨日上网偶遇了这个题目,思考了一下,给出了一种笨办法:
<方法1> 思路:通过分组+排序+limit函数分别求出每个部门的薪资前三名,再通过union合并
mysql> (select e.ename,e.deptno,e.salfrom emp e where deptno="10" order by sal desc limit 3)
-> union
-> (select e.ename,e.deptno,e.sal from emp e wheredeptno="20" order by sal desc limit 3)
-> union
-> (select e.ename,e.deptno,e.sal from emp e wheredeptno="30" order by sal desc limit 3);
执行结果:
+--------+--------+---------+
| ename | deptno |sal |
+--------+--------+---------+
| KING | 10 | 5000.00 |
| LARK | 10 | 3200.00 |
| CLARK | 10 | 2450.00 |
| FORD | 20 | 3000.00 |
| SCOTT | 20 | 3000.00 |
| JONES | 20 | 2975.00 |
| BLAKE | 30 | 2850.00 |
| ALLEN | 30 | 1600.00 |
| TURNER | 30 | 1500.00 |
+--------+--------+---------+
虽然可以成功实现,但代码过于冗长,且处理多部门的情形会很会吃力。在CSDN上看到另一种做法:
<方法2>
mysql>
select e.ename, e.deptno,e.sal
from emp e
where (select count(*) from emp em where em.sal>e.sal and em.deptno=e.deptno)<3
order by e.deptno,e.sal desc;
执行结果和方法1相同。
毫无疑问,方法2更加简洁高效。那么,怎么理解方法2的逻辑呢?重点在于对count语句条件的理解。
where (select count(*) from emp em where em.sal>e.sal and em.deptno=e.deptno)<3
执行上述语句时,系统会把同一个deptno下每一个的e.sal值与em.sal值进行逐一比对,然后通过count函数来计算符合条件的值的个数。这里的判定条件为<3,所以上述语句实际是包含了三种情形:count(...)is in(0,1,2),下面分别考察。
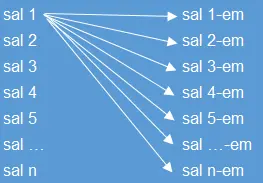
Count(...) = 0:意味着e表取出来的某个值在与em表逐个比对的过程中没有一条线的比对结果是True,即e表中取出的这个值在所有的比对情形中均大于或等于em表,哪一个值会出现这种比对结果呢?最大值。所以,通过count=0的判定情形,我们筛选出了同一deptno下sal的最大值。
Count(...) = 1:意味着e表取出来的某个值在与em表逐个比对的过程中有一条线e的比对结果是True,即em表中有仅1个值是大于e表中取出的这个值的。不难理解,通过这个判定情形我们实际筛选出了第二名。
Count(...) = 2:以此类推,第三名也被筛选出来了。
方法2的语句扩展性很强,比如稍作修改,即可对每个部门薪资排名倒数前三进行筛选:
mysql> select e.ename, e.deptno,e.sal
-> from -> emp e
-> where (select count(*) from emp em where em.sal<e.sal and em.deptno=e.deptno)<3
-> order by e.deptno,e.sal;
执行结果:
+--------+--------+---------+
| ename | deptno | sal |
+--------+--------+---------+
| MILLER | 10 | 1300.00 |
| CLARK | 10 | 2450.00 |
| LARK | 10 | 3200.00 |
| SIMITH | 20 | 800.00 |
| ADAMS | 20 | 1100.00 |
| JONES | 20 | 2975.00 |
| JAMES | 30 | 950.00 |
| WARD | 30 | 1250.00 |
| MARTIN | 30 | 1250.00 |
+--------+--------+---------+

 技术文档
技术文档
 推荐好文
推荐好文







 155-2731-8020
155-2731-8020